Hydaway Digital Corp.在其RealityChek平台推出流媒体音频检测功能,能够实时识别合成或篡改的音频,适用于实时电话和呼叫中心等场景,帮助企业在欺诈发生前进行检测,提升安全性。该系统通过分析频谱模式和韵律标记等特征,实时评估音频的真实性,符合Hydaway推动实时信任决策的战略目标。
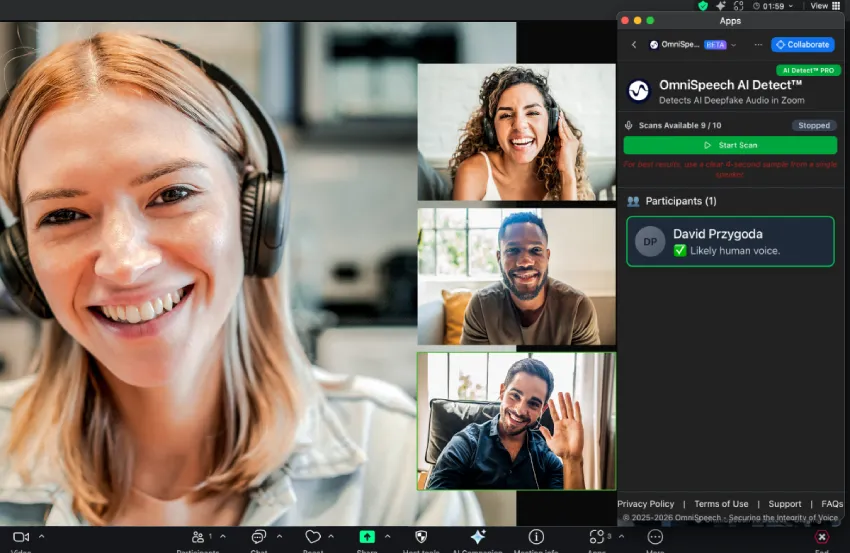
OmniSpeech 将实时深度伪造音频检测功能集成到 Zoom,用户可以实时识别 AI 生成或篡改的音频,适用于远程面试和财务授权等场景,确保语音的真实性。
本研究建立了多类型深度伪造音频检测基准,采用波形提示调优的自监督学习方法,优化检测效果,平均错误率为3.58%。
本研究提出了一种名为区域优化(RegO)的持续学习方法,以提高音频深度伪造检测的有效性。该方法通过优化重要神经区域,平衡存储稳定性与学习灵活性,实验结果显示错误接受率提高了21.3%。
本文介绍了深度伪造音频检测模型的研究进展,包括基于深度学习的音频数据集、MFAAN网络、实时检测模型和多模态融合方法。这些研究提高了伪音频检测的准确性,展示了在动态通信场景中确保音频安全的潜力。
本文提出了一种名为时序深度伪造定位(TDL)的音频检测方法,结合嵌入相似度模块和时序卷积,能够有效识别伪造音频的真实性。研究表明,该方法在ASVspoof2019数据集上表现优异,为音频篡改检测提供了新的思路。
该研究聚焦于深度伪造音频的检测,提出了CSAM策略以解决领域偏差问题,并通过新数据集实现了最低0.616%的等错误率。研究还开发了FakeAVCeleb数据集,旨在应对深度伪造技术带来的安全隐患,推动多模态检测器的发展。此外,提出了基于Resnet和LCNN架构的实时检测模型,提升了音频流的安全性。
本文介绍了结合对比学习和深度学习的方法,以提高卷积神经网络在音频和图像伪造检测中的性能。研究表明,这种结合可以有效减轻背景偏差、增强模型鲁棒性,并在多个数据集上实现显著性能提升。
完成下面两步后,将自动完成登录并继续当前操作。