

xAI Grok音频模型现已在Vercel AI Gateway上线
Vercel News
·

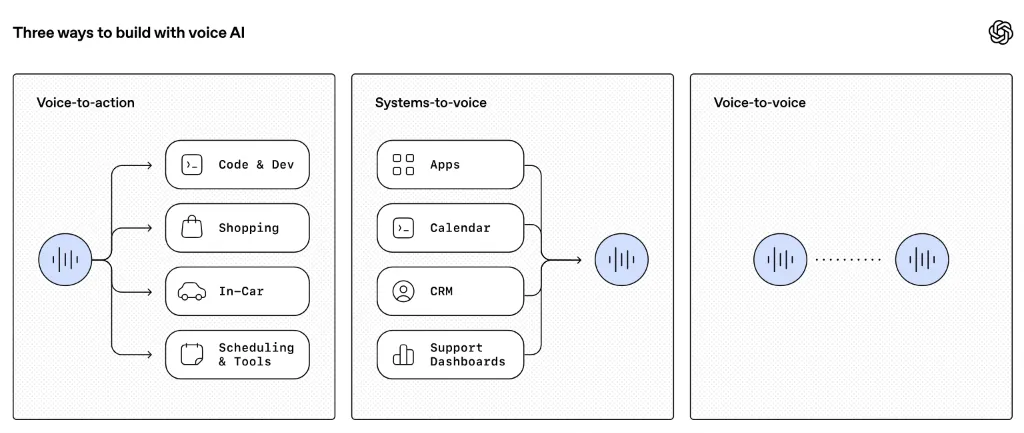

通过API中的新模型推动语音智能发展
OpenAI
·


谷歌的Gemini Live AI助手将向您展示它所谈论的内容
The Verge
·

在API中推出新一代音频模型
OpenAI
·

