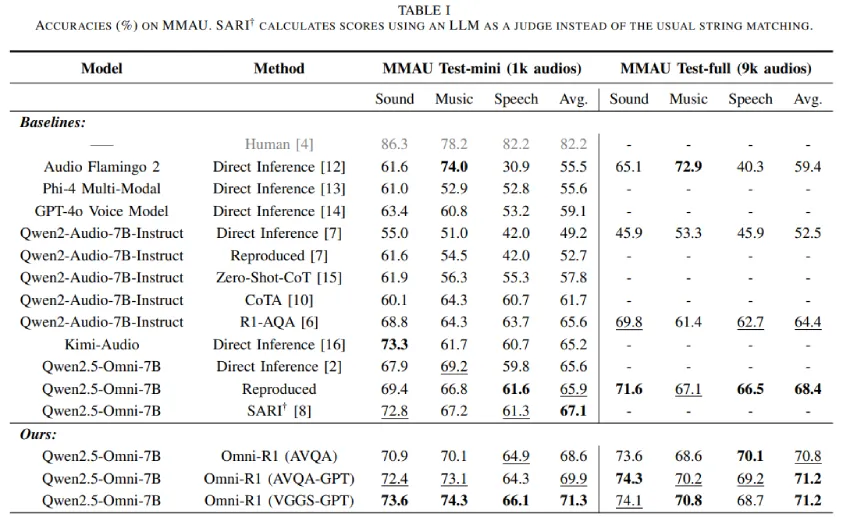
近期研究表明,强化学习显著提升了音频 LLM 的推理能力。通过 GRPO 方法微调 Qwen2.5-Omni 模型,研究人员在 MMAU 基准测试中取得最佳成绩。仅使用文本数据微调也显著提升了性能,强调了文本推理的重要性。此外,研究生成了两个大规模音频问答数据集,进一步提高了模型的准确性。
本研究针对DCASE 2025挑战的任务五,定义了三个子集,以评估音频语言模型在复杂场景中的问答能力,旨在提升其理解与推理能力。
完成下面两步后,将自动完成登录并继续当前操作。