
Omni-R1:利用文本驱动的强化学习和自动生成的数据推进音频问答
内容提要
近期研究表明,强化学习显著提升了音频 LLM 的推理能力。通过 GRPO 方法微调 Qwen2.5-Omni 模型,研究人员在 MMAU 基准测试中取得最佳成绩。仅使用文本数据微调也显著提升了性能,强调了文本推理的重要性。此外,研究生成了两个大规模音频问答数据集,进一步提高了模型的准确性。
关键要点
-
强化学习显著提升了音频 LLM 的推理能力。
-
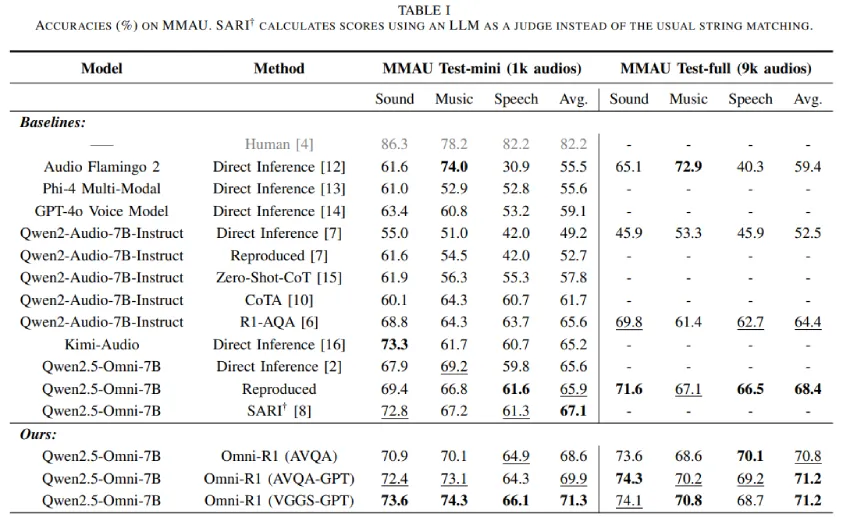
研究使用 GRPO 方法微调 Qwen2.5-Omni 模型,在 MMAU 基准测试中取得最佳成绩。
-
仅使用文本数据微调也显著提升了模型性能,强调了文本推理的重要性。
-
研究生成了两个大规模音频问答数据集,进一步提高了模型的准确性。
-
Omni-R1 模型基于 GRPO 强化学习方法进行微调,允许直接选择答案,节省了 GPU 内存。
-
GRPO 通过基于答案正确性的奖励来比较分组输出,避免了价值函数。
-
使用 ChatGPT 生成的 AVQA-GPT 和 VGGS-GPT 数据集提升了模型性能。
-
Qwen2.5-Omni 在没有音频的情况下也表现出强大的推理能力,显示出其基于文本的理解能力。
-
研究结果表明,文本推理能力的增强是性能提升的主要原因。
-
这些发现为开发支持音频的语言模型提供了经济高效的策略。
延伸解读
强化学习的优势
本研究表明,强化学习在提升音频 LLM 的推理能力方面具有显著效果。通过 GRPO 方法微调 Qwen2.5-Omni 模型,研究人员在 MMAU 基准测试中取得了最佳成绩。这一发现强调了强化学习在多模态模型中的重要性,尤其是在处理复杂的音频问答任务时。
文本推理的重要性
研究发现,仅使用文本数据进行微调,模型性能几乎与使用音频和文本训练的效果相同。这表明,文本推理能力的增强是提升音频问答性能的关键因素。开发者在设计音频 LLM 时,应重视文本数据的使用,以提高模型的整体表现。
数据集的自动生成
研究团队使用 ChatGPT 自动生成了两个大规模音频问答数据集,AVQA-GPT 和 VGGS-GPT。这种方法不仅提升了模型的准确性,还为未来的研究提供了新的数据来源。自动生成数据集的策略为音频 LLM 的训练提供了经济高效的解决方案,值得其他研究者借鉴。
延伸问答
Omni-R1模型的主要创新点是什么?
Omni-R1模型基于GRPO强化学习方法进行微调,显著提升了音频问答能力,并在MMAU基准测试中取得最佳成绩。
GRPO方法如何影响模型的推理能力?
GRPO方法通过基于答案正确性的奖励来比较分组输出,主要增强了模型的基于文本的推理能力,从而显著提升性能。
研究中生成了哪些音频问答数据集?
研究生成了两个大规模音频问答数据集,分别是AVQA-GPT和VGGS-GPT,进一步提升了模型的准确性。
仅使用文本数据微调模型的效果如何?
仅使用文本数据对模型进行微调,其效果几乎与使用音频和文本进行训练的效果相同,显示出文本推理的重要性。
Omni-R1在MMAU基准测试中的表现如何?
Omni-R1在MMAU基准测试中,在声音、语音、音乐和整体表现方面均取得了新的最佳成绩。
研究结果对音频语言模型的开发有什么启示?
研究结果表明,增强的文本推理能力是性能提升的主要原因,为开发支持音频的语言模型提供了经济高效的策略。
