LaDiR(潜在扩散推理器)是一种新颖的推理框架,结合了连续潜在表示的表达能力与潜在扩散模型的迭代精炼能力。通过变分自编码器(VAE)构建的结构化潜在推理空间,LaDiR在数学推理和规划基准测试中展现出更高的准确性、多样性和可解释性,开辟了文本推理的新范式。
谷歌推出MedGemma模型,旨在革新医疗行业。该模型基于Gemma 3架构,支持医学文本和图像数据,适合开发诊断助手和报告生成工具。MedGemma 4B为多模态模型,27B专注于文本推理,适用于临床总结和复杂查询。指南提供了在本地或GPU上安装和运行模型的详细步骤。
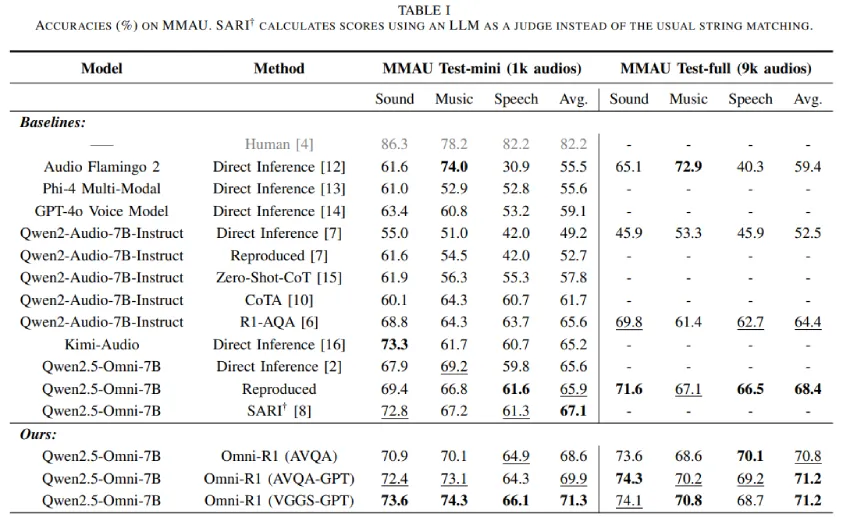
近期研究表明,强化学习显著提升了音频 LLM 的推理能力。通过 GRPO 方法微调 Qwen2.5-Omni 模型,研究人员在 MMAU 基准测试中取得最佳成绩。仅使用文本数据微调也显著提升了性能,强调了文本推理的重要性。此外,研究生成了两个大规模音频问答数据集,进一步提高了模型的准确性。
Gemma 3是Google DeepMind推出的轻量级开源模型,支持140种语言,具备先进的文本和视觉推理能力。该模型适用于单个GPU或TPU,具有128k-token上下文窗口和函数调用功能,性能优越。此外,Gemma 3还推出了量化版本,以减少计算需求,并与ShieldGemma 2一起提供图像安全检查,促进负责任的AI开发。
Gemma家族推出的开源模型Gemma 3,支持140种语言,具备先进的文本和视觉推理能力,适用于多种设备。新模型引入了ShieldGemma 2,提供图像安全检查,并优化了性能,支持多种开发工具,旨在推动负责任的AI开发。
本研究提出EXPLORA算法,旨在解决文本及混合源的复杂推理示例选择问题,减少大语言模型调用次数约11%,性能提升12.24%。
本研究探讨了大型语言模型(LLMs)在生成结构化表格数据文本中的性能,提出了表格结构归一化方法,并比较了文本推理与符号推理。研究发现,LLMs在处理和生成表格数据方面具有潜力,但面临社会偏见和生成准确性等挑战。通过实验,提出了改进模型训练和合成数据生成的策略,强调了LLMs在数据科学中的实际应用意义。
本文探讨了大型语言模型(LLMs)在上下文学习中的应用,提出通过优化提示和演示选择策略来提升对话生成和文本推理任务的性能。研究表明,调整提示和多样化演示能显著改善生成质量,增加演示数量即使在演示存在缺陷时也能提高效果。
本文比较了不同粒度的事实性分值应用,提出了一种基于证明的文本蕴涵树方法,显著提高了文本推理的准确性。研究表明,将复杂任务分解为子任务能有效提升大型语言模型的性能,并在金融新闻时态性检测和情感分析中取得了较高的精确度。此外,提出的时间推理模型在事件预测和解释方面表现优异。
该研究提出了一种基于关联记忆的新架构,增强了循环神经网络(AM-RNNs),并扩展为双序列建模的Dual AM-RNN,取得了优异的文本推理结果。研究还介绍了多种增强记忆的神经网络模型,展示了它们在语言建模和图像分类等任务中的优越性,强调了增强记忆模型相较于传统RNN的优势。
研究发现大型语言模型在解释和推理表格数据方面的能力,并提出了表格结构归一化的方法。通过比较文本推理和符号推理,取得了在WIKITABLEQUESTIONS任务上的最新成果。
完成下面两步后,将自动完成登录并继续当前操作。