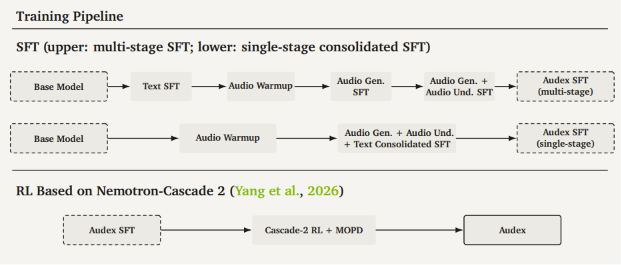
NVIDIA 发布了 Audex,这是一个统一的音频-文本大型语言模型,具备理解和生成音频及语音的能力,同时保持文本智能。Audex 采用 30 亿参数的 MoE 结构,设计简洁,避免了多模态模型的性能退化,在文本和音频任务中表现优异,尤其在语音识别领域领先。尽管存在商业许可限制和音频理解能力不足等缺点,Audex 仍在多项任务中表现出色。
本研究提出CLASP(对比语言-语音预训练),旨在解决音频-文本信息检索中的多语言多模态表示问题。该方法结合语音和文本数据,构建了15个类别的数据集,设立了新基准,显示出优于传统语音识别方法的潜力。
该研究提出了一种音频-文本交叉模态表示提取器,利用注意力机制提升智能语音识别(ASR)性能。通过上下文注入和数据增强技术,显著改善了情感语音的识别效果,并降低了词错误率(WER)。研究还探讨了自然语音识别噪音对信息检索的影响,并提出了解决方案以提高口头语言理解的鲁棒性。
完成下面两步后,将自动完成登录并继续当前操作。