研究团队提出SafeKey框架,显著提升大型推理模型的安全性,降低9.6%的风险率,同时保持核心能力。通过分析“关键句”和“沉睡的安全信号”,优化模型的安全决策,增强其自主性和稳健性。
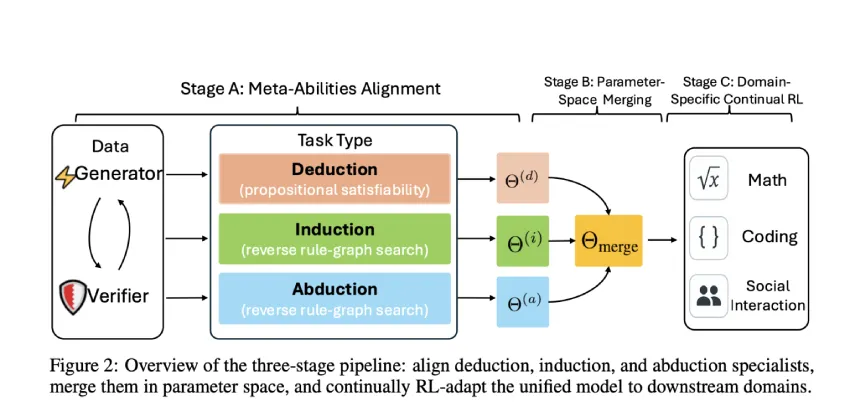
大型推理模型(LRM)通过结构化强化学习提升推理能力,克服了依赖“顿悟时刻”的局限性。研究者提出了结合演绎、归纳和溯因推理的三阶段流程,显著提高了模型在数学和编程任务中的表现。
TinyLLaVA-Video-R1是一个小规模的视频推理模型,展示了在视频问答数据集上通过强化学习实现的强大推理能力。研究表明,该模型不仅能有效推理视频内容,还具备“顿悟”特征,表现出反思和自我修正的能力。这一进展为资源有限的AI研究开辟了新方向。
本研究解决了在多模态推理中复制复杂推理特征的挑战。通过在非SFT的2B模型上直接应用强化学习,我们成功实现了“顿悟”瞬间,并在CVBench上达到59.47%的准确率,较基线模型提高约30%。该工作的潜在影响在于为多模态推理的发展提供了新思路,同时揭示了传统方法的局限性。
自我反思对模型性能的提升有限。研究表明,DeepSeek-R1-Zero通过强化学习实现了“顿悟”,但自我反思并不总能提高答案的准确性,肤浅自我反思(SSR)可能导致错误答案。模型在训练初期就能表现出自我反思,但并非所有反思都是有效的。
文章探讨了如何有效进行冲刺回顾,以促进团队讨论和流程改进。通过分析成功与不足,制定具体行动计划,团队能够将“糟糕时刻”转变为“顿悟时刻”。使用如devActivity等工具提供实时数据,帮助识别问题并优化未来冲刺。
从社会科学转向编程让我领悟到编程的独特魅力,包括顿悟时刻、逻辑美、可实现的成果、成为大师的过程以及良好的职业前景。这些因素激励我追求成为优秀程序员,热爱编程让我感受到工作的意义与影响。
文章探讨了产品工程师角色的变化,强调软件工程师需关注客户问题,而不仅是编程。随着AI的发展,传统编程角色逐渐消失,工程师需回答三个核心问题:问题是什么?为谁解决?为何重要?通过这些问题,工程师可以成为产品决策者。团队合作也很重要,工程师应利用团队资源推动决策和创新。
习武需要渐进的努力和顿悟的领悟。渐进的努力需要耗费时间和精力,顿悟则是由量变到质变。然而,有些人只记住几句话就想走捷径。
完成下面两步后,将自动完成登录并继续当前操作。