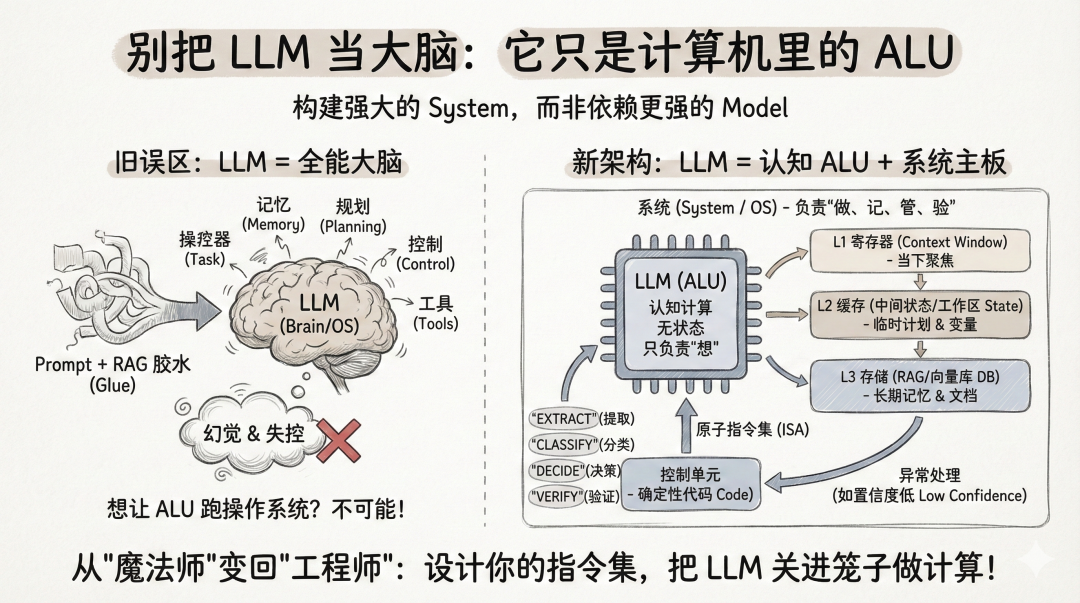
大语言模型(LLM)如ChatGPT并非全能,而是概率生成工具。开发者应将其视为“算术逻辑单元”,而非“大脑”。应分离认知计算与系统管理,构建更强的系统架构,而非单纯依赖更强的模型。
本文从理论的角度分析了对抗攻击周围的逻辑差异,并提出了一种新的原则,即 Adversarial Logit Update (ALU),用于推断对抗样本的标签。基于ALU,引入了一种新的分类范式,利用预净化和后净化的逻辑差异来提高模型的对抗鲁棒性。实验证明,该解决方案在CIFAR-10、CIFAR-100和tiny-ImageNet数据集上具有卓越的鲁棒性能。
完成下面两步后,将自动完成登录并继续当前操作。