
做智能体时,别把 LLM 当大脑:它是计算机里的 ALU,而你需要构建的是操作系统
内容提要
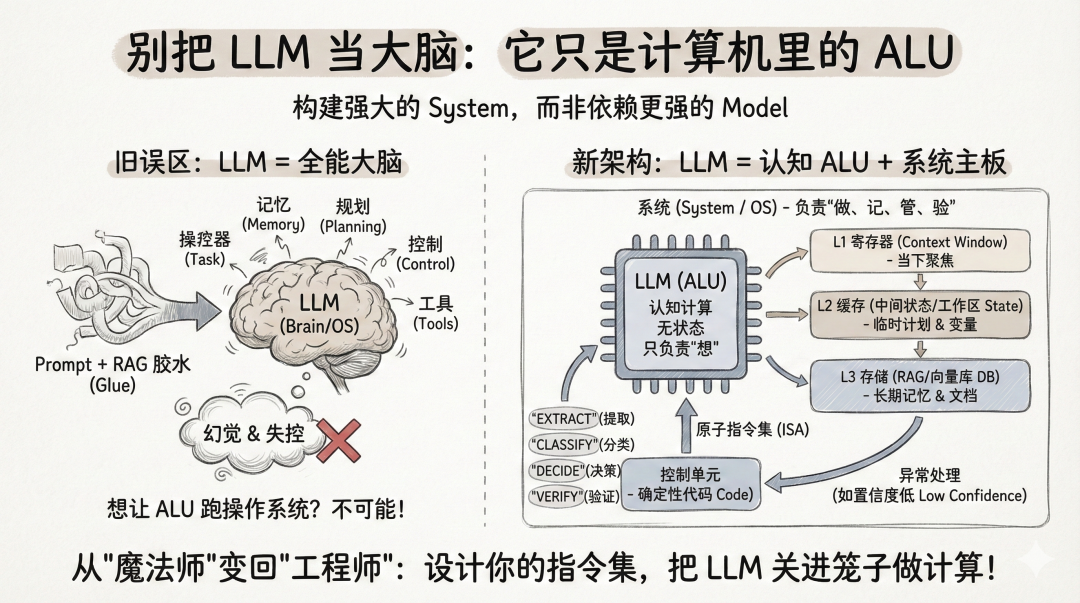
大语言模型(LLM)如ChatGPT并非全能,而是概率生成工具。开发者应将其视为“算术逻辑单元”,而非“大脑”。应分离认知计算与系统管理,构建更强的系统架构,而非单纯依赖更强的模型。
关键要点
-
大语言模型(LLM)如ChatGPT并非全能,而是概率生成工具。
-
开发者应将LLM视为算术逻辑单元(ALU),而非大脑或操作系统。
-
需要将认知计算与系统管理分离,构建更强的系统架构。
-
RAG(检索增强生成)并不是记忆,而是语义检索,需分层设计记忆结构。
-
应定义原子的认知指令集,类似于计算机汇编语言。
-
需要建立认知异常处理机制,像处理CPU溢出一样处理LLM错误。
-
AI Agent的下一阶段是构建更强的系统架构,而非等待更强的模型。
延伸解读
LLM的角色定位
文章强调大语言模型(LLM)应被视为算术逻辑单元(ALU),而非全能的大脑。这一定位提醒开发者在构建AI Agent时,需明确LLM的局限性,避免将其用于超出其能力范围的任务,如记忆管理和任务规划。
记忆与RAG的误区
RAG(检索增强生成)被误解为记忆,实际上它更像是语义检索。文章指出,开发者应重视记忆的分层设计,避免将上下文视为简单的文本堆砌,而应构建可追溯的结构化状态,以提高系统的可靠性。
认知指令集的重要性
文章提到,未来的Agent开发应借鉴计算机汇编语言,定义原子的认知指令集。这种方法将使得开发过程更具确定性,减少对LLM的依赖,从而提高系统的可控性和可调试性。
延伸问答
为什么大语言模型(LLM)不能被视为全能的大脑?
大语言模型本质上是概率生成工具,主要负责词语接龙,而非全面的认知处理能力。
如何将LLM与系统管理分离以构建更强的AI Agent?
需要将认知计算与系统管理彻底分离,LLM负责计算,系统负责记忆和任务管理。
RAG在AI系统中的作用是什么?
RAG并不是记忆,而是语义检索,类似于持久化存储,需分层设计记忆结构。
如何定义认知指令集以提高AI Agent的效率?
应定义原子的认知指令集,如EXTRACT、CLASSIFY、DECIDE等,以实现更高效的操作。
如何处理LLM的错误以构建可靠的系统?
应建立认知异常处理机制,像处理CPU溢出一样,外部代码捕获和处理LLM的错误。
未来的AI Agent开发应关注哪些方面?
未来应关注构建更强的系统架构,而非单纯等待更强的模型,强调设计内存总线和指令集。
