
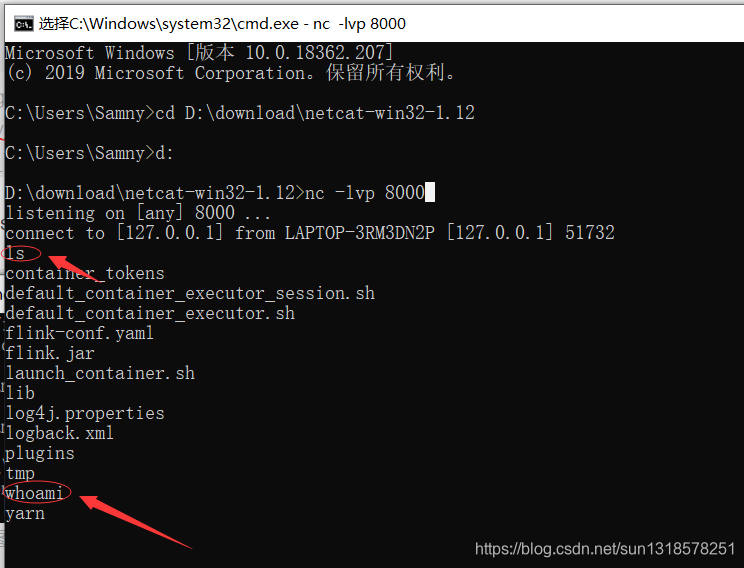
Apache Flink任意Jar包上传导致远程代码执行
像清水一般清澈透明
·

基于华为开发者空间-云开发环境Docker+Flink实现大数据实时统计系统
华为云官方博客
·

使用Apache Flink构建真实的企业AI代理
The New Stack
·

演讲:Apache Flink中的流处理与批处理融合
InfoQ
·

基于亚马逊云科技托管 Flink 的开发系列 — MySQL CDC 写入数据湖篇
亚马逊AWS官方博客
·
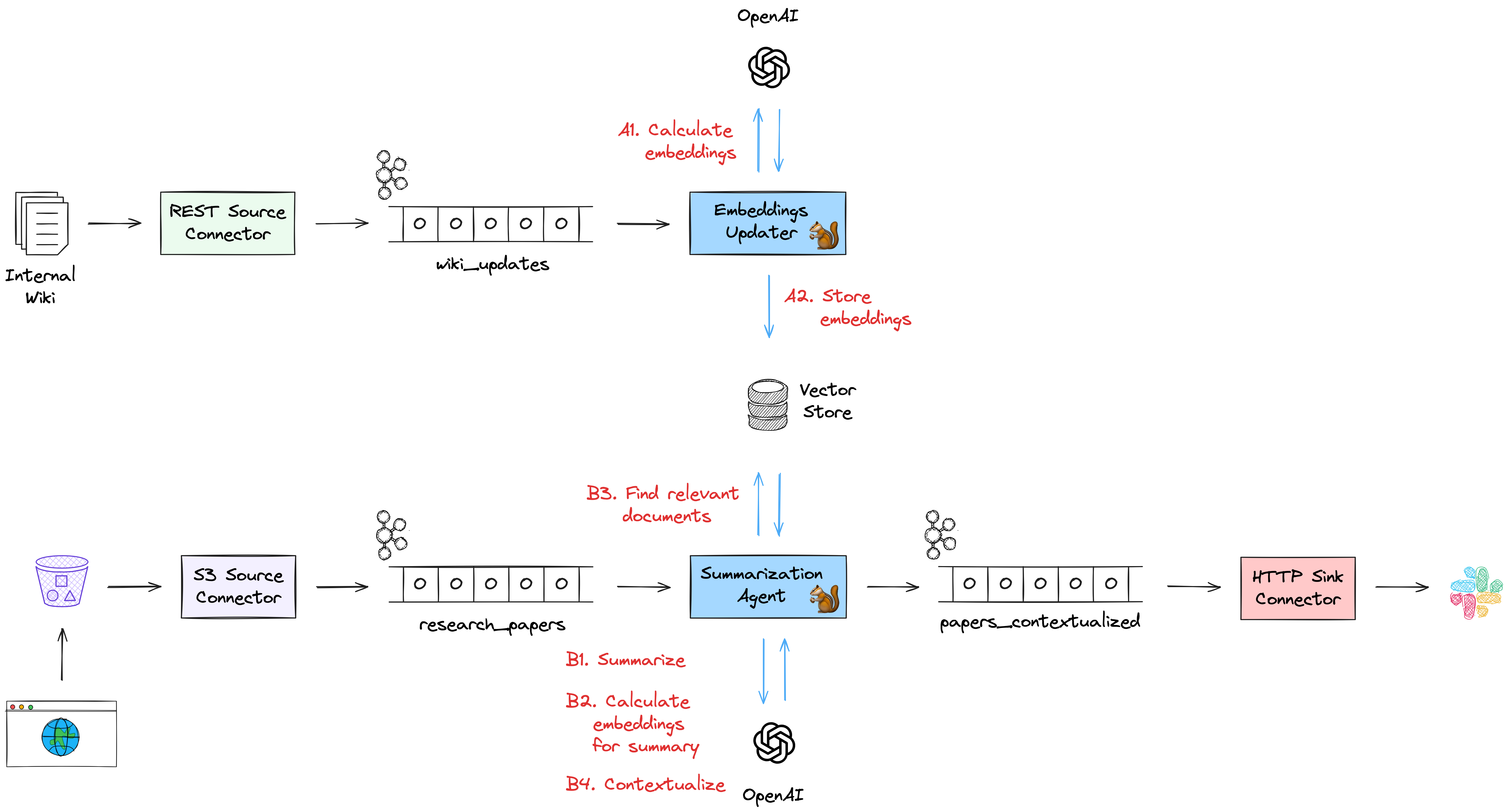
这个AI代理本该是一个SQL查询
morling.dev -- Blog
·
使用 Amazon Q Developer CLI 快速搭建各种场景的 Flink 数据同步管道
亚马逊AWS官方博客
·

什么是Apache Flink?探索其开放源代码商业模式、资金和社区
DEV Community
·



如何利用窗口聚合和机器学习推断处理物联网传感器数据
DEV Community
·

使用Apache Flink实现实时数据处理
DEV Community
·

实时人工智能应用:使用Apache Flink进行模型推理
The New Stack
·

Amazon托管的Apache Flink服务
DEV Community
·

在数据工程中使用Apache Flink进行实时流处理
DEV Community
·
基于亚马逊云科技托管 Flink 的开发系列 — SSL 认证的 Kafka 读取篇
亚马逊AWS官方博客
·
