

介绍 Apache Spark 4.2
Databricks
·
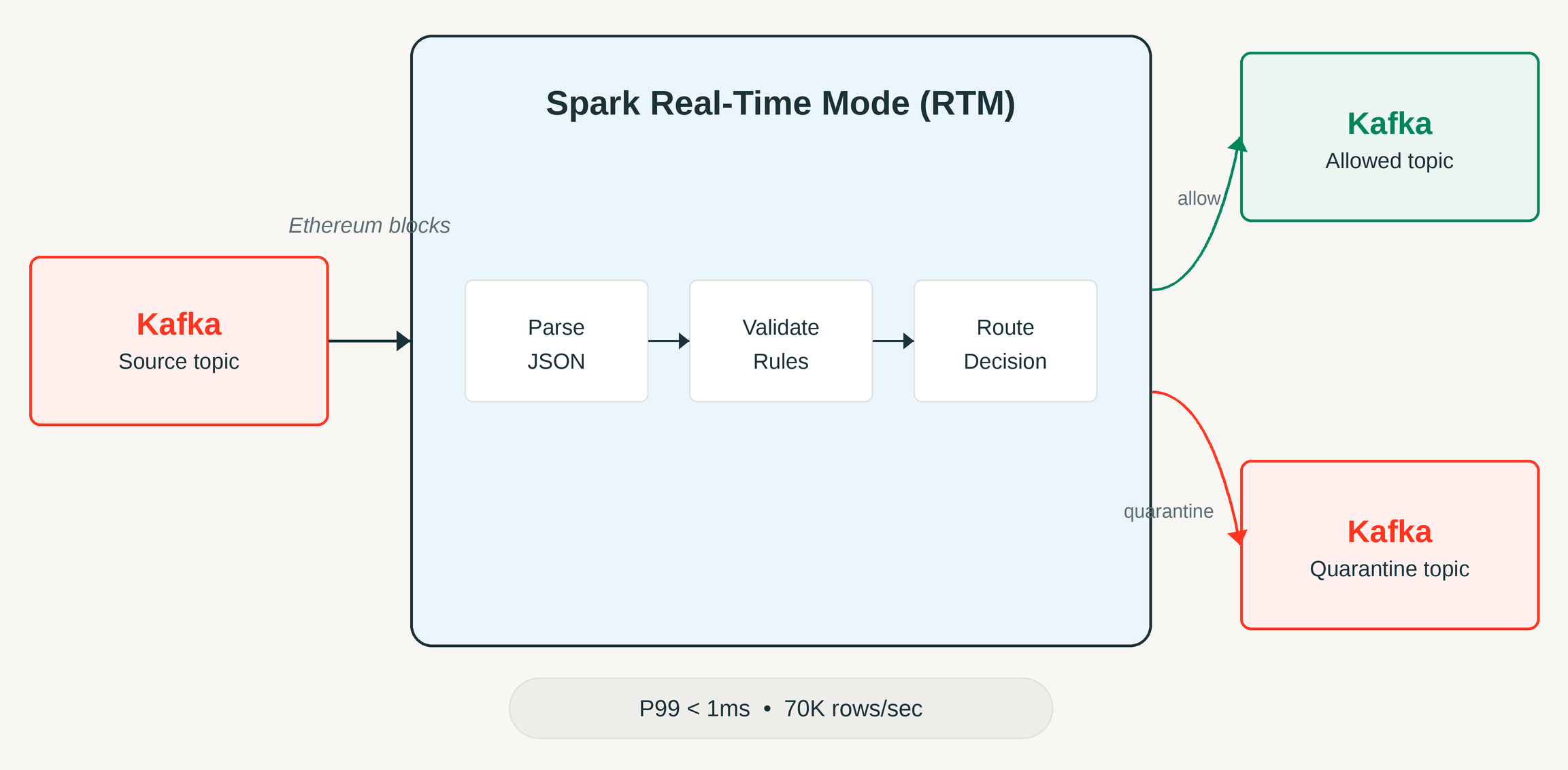
基于Apache Spark实时模式的超快速异常检测
Databricks
·
Apache®软件基金会宣布新的顶级项目
The Apache Software Foundation Blog
·
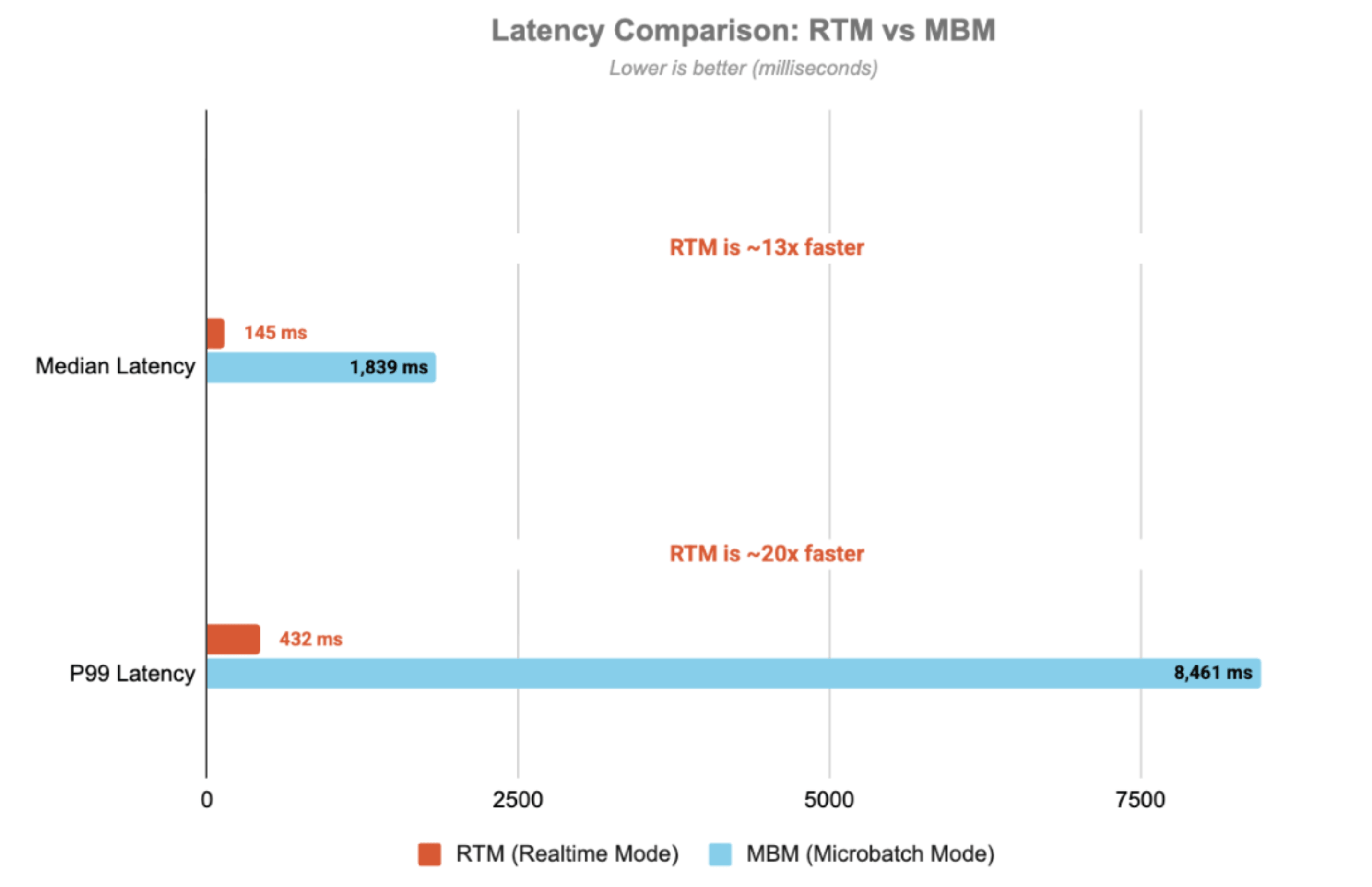
游戏行业中的Apache Spark实时模式:更好的实时会话处理方式
Databricks
·

重新思考无服务器性能和可靠性的分布式系统
Databricks
·
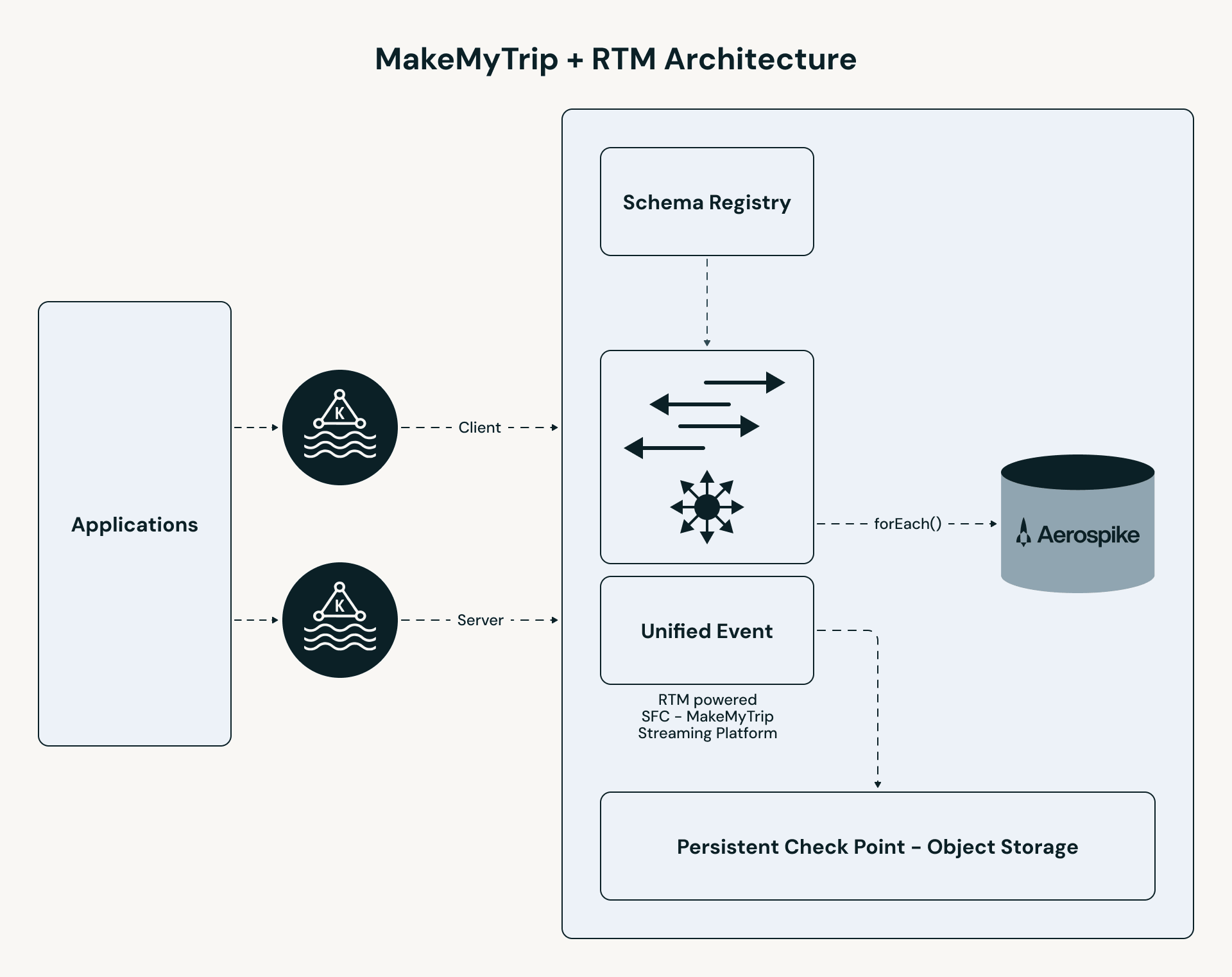
MakeMyTrip如何通过Databricks实现大规模毫秒级个性化
Databricks
·

打破微批障碍:Apache Spark实时模式的架构
Databricks
·

Apache软件基金会将两个开源项目从孵化器毕业
The Apache Software Foundation Blog
·
Agoda如何建立统一的财务数据源
ByteByteGo Newsletter
·

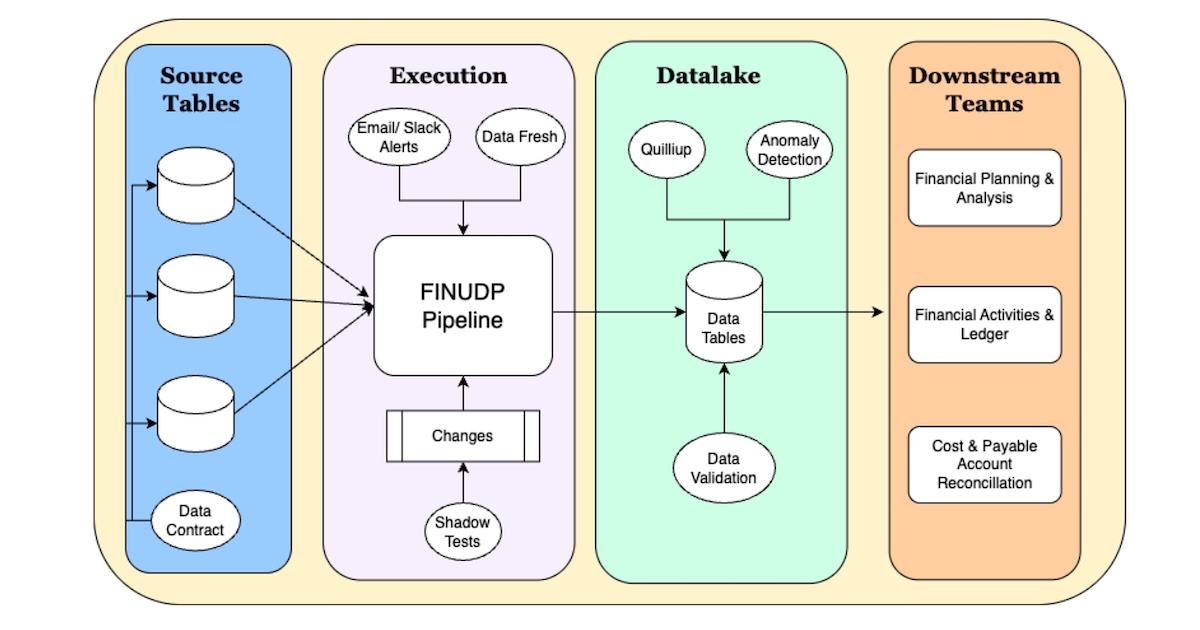
Agoda如何将多个数据管道整合为单一真实数据源
InfoQ
·
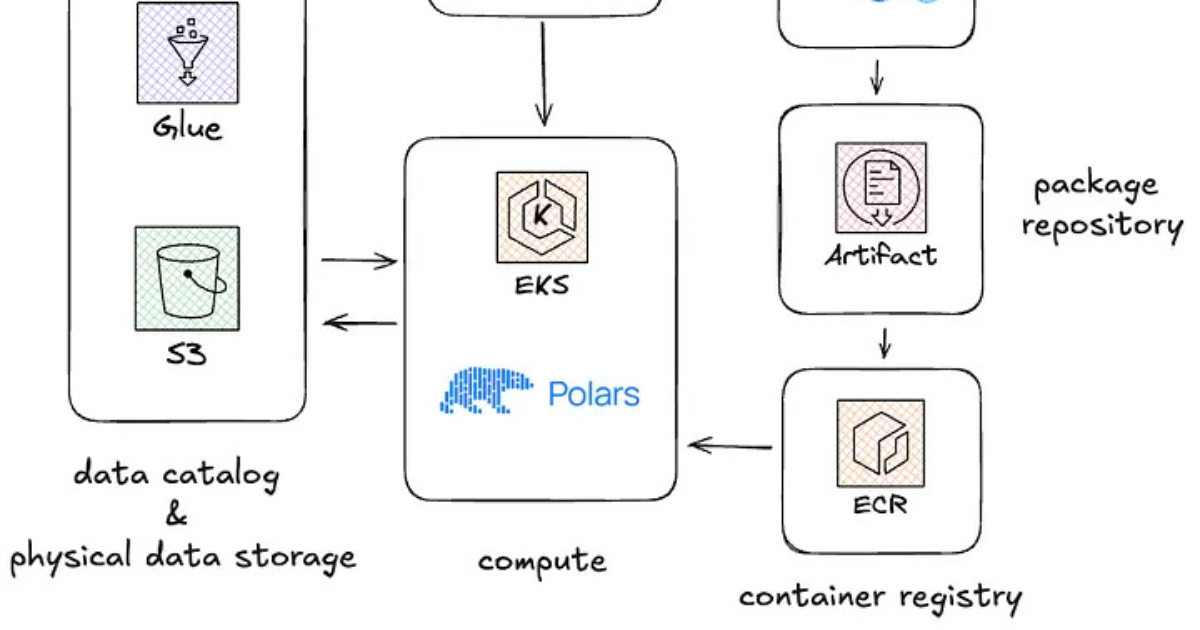
迪卡侬切换至Polars以优化数据管道和基础设施成本
InfoQ
·

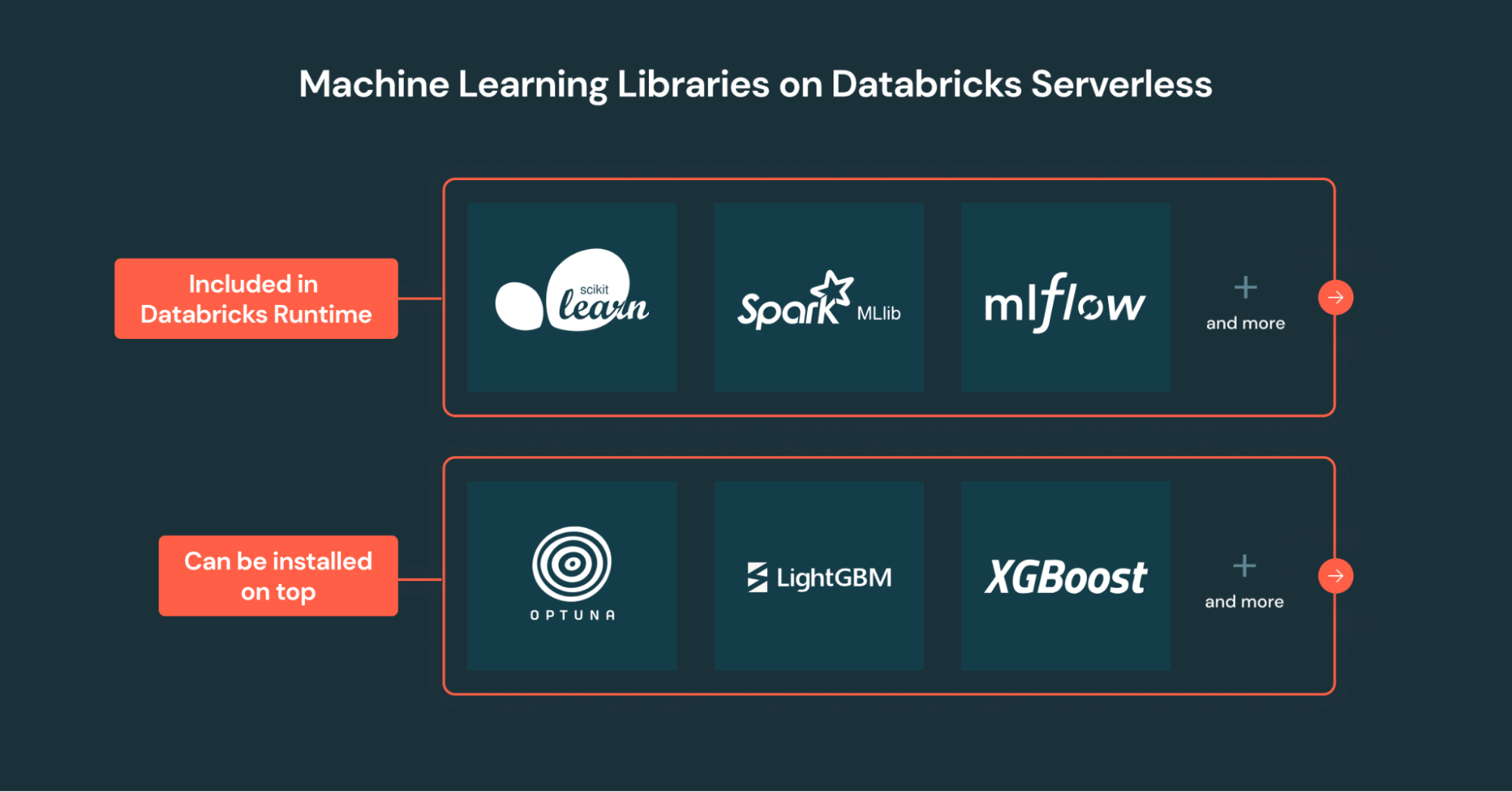
宣布无服务器和标准集群上分布式机器学习的公共预览
Databricks
·

从滞后到敏捷:重塑Freshworks的数据摄取架构
Databricks
·

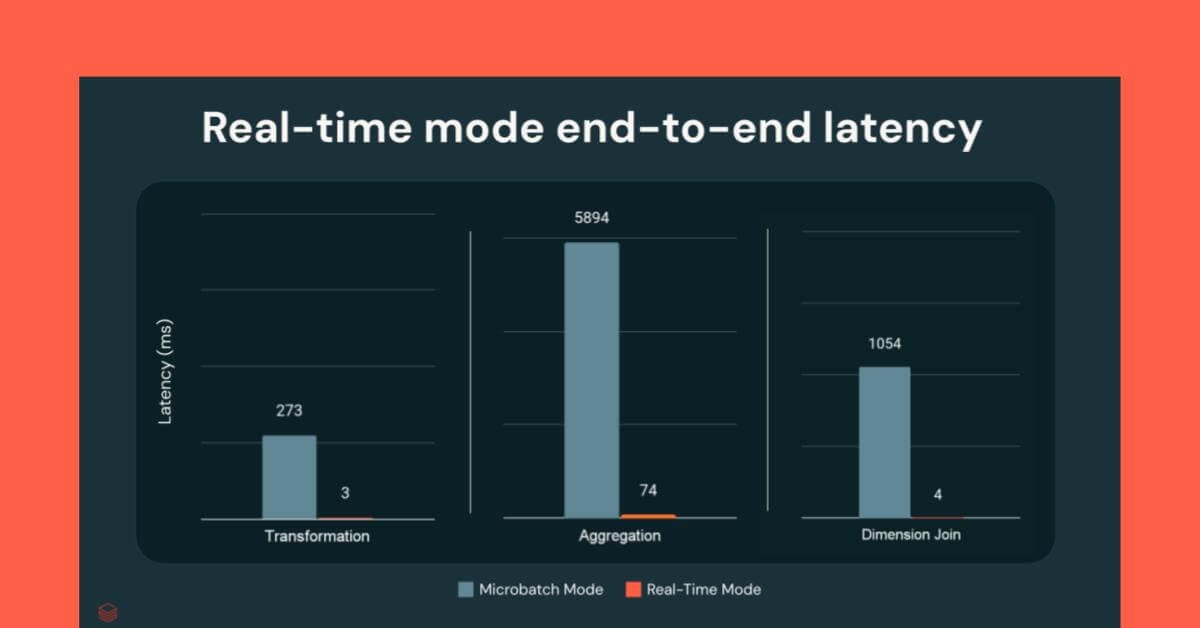

使用新型transformWithState API进行持续环境监测
Databricks
·

