
迪卡侬切换至Polars以优化数据管道和基础设施成本
内容提要
迪卡侬通过使用开源库Polars优化数据管道,发现其在处理小于50 GiB的数据时,比Apache Spark更快且成本更低。尽管在Kubernetes上运行Polars存在挑战,但其效率显著提升。
关键要点
-
迪卡侬采用开源库Polars优化数据管道,发现其在处理小于50 GiB的数据时比Apache Spark更快且成本更低。
-
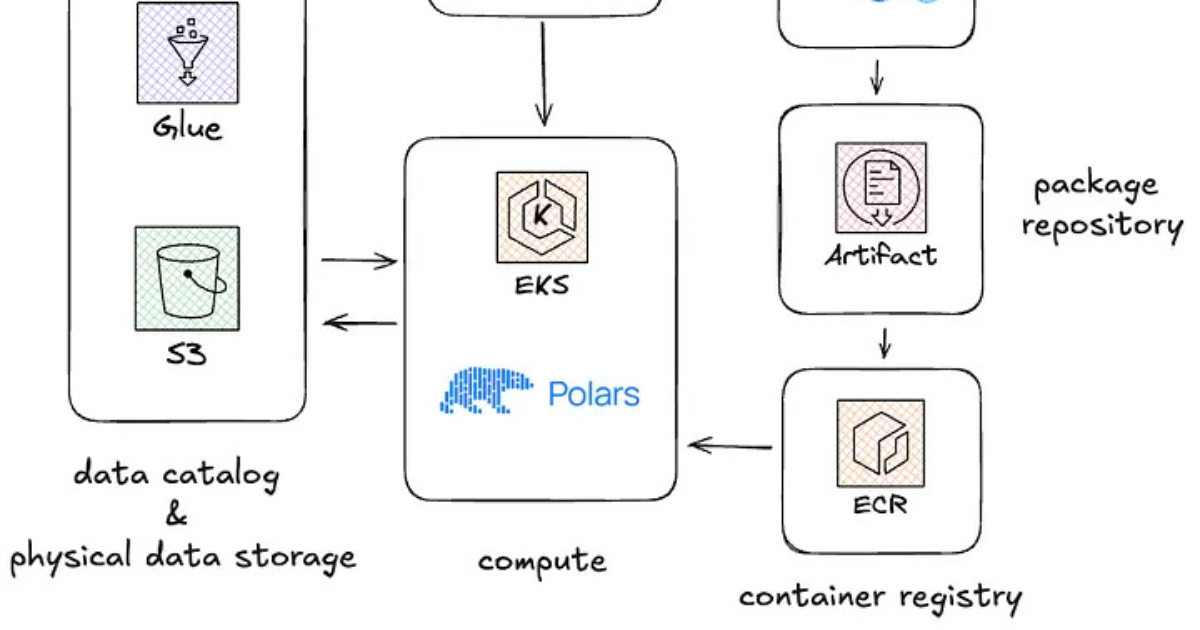
迪卡侬的数据平台在云集群上运行PySpark工作流,数据存储为Delta表,使用AWS Glue作为技术元存储。
-
虽然该解决方案针对大数据作业进行了优化,但对于较小的数据集(千兆字节或兆字节)来说被认为是次优的。
-
数据团队开始尝试使用Polars处理较轻或中等大小的工作负载,最初是为了替代遇到扩展问题的pandas工具。
-
Polars的语法与Spark相似,团队决定将一个约50 GiB的Parquet表的Spark作业迁移到Polars。
-
从Spark云托管集群迁移到单节点Kubernetes pod后,计算启动时间从8分钟减少到2分钟。
-
启用Polars的新流处理引擎后,数据集处理效率显著提升,单个Kubernetes pod上作业运行效率高。
-
团队决定在所有新管道中实施Polars,前提是输入表小于50 GiB,大小稳定且不涉及多个连接或复杂聚合。
-
在Kubernetes上运行Polars存在挑战,需要团队学习如何运行容器服务,并可能导致数据管道在团队之间的跳转变慢。
-
Vennin强调Polars无法读取某些数据集的额外限制,例如使用Liquid Clustering或Column Mapping特性的情况。
延伸解读
Polars的优势与局限
迪卡侬选择Polars主要是为了处理小于50 GiB的数据集,因其在速度和成本上优于Apache Spark。然而,Polars并不适合所有场景,特别是涉及复杂聚合或多个连接的任务。因此,团队需谨慎评估数据集的特性,以决定是否使用Polars。
Kubernetes上的挑战
虽然Polars在单节点Kubernetes pod上运行效率高,但在Kubernetes环境中部署Polars也带来了新的挑战。团队需要学习如何管理容器服务,这可能导致数据管道在团队之间的流转变慢。因此,团队在实施Polars时需考虑这些管理和安全方面的因素。
数据处理架构的演变
迪卡侬的数据平台采用了Medallion架构来优化数据质量和治理。随着Polars的引入,团队能够更高效地处理小型数据集,这表明数据处理架构正在向更灵活和高效的方向发展。未来,如何平衡不同工具的使用将是关键。
延伸问答
迪卡侬为什么选择使用Polars来优化数据管道?
迪卡侬选择Polars是因为它在处理小于50 GiB的数据时比Apache Spark更快且成本更低。
Polars在数据处理方面有哪些优势?
Polars的优势包括更快的计算速度和更低的成本,尤其是在处理小型数据集时。
在Kubernetes上运行Polars存在哪些挑战?
在Kubernetes上运行Polars的挑战包括需要学习如何管理容器服务,并可能导致数据管道在团队之间的跳转变慢。
迪卡侬的数据平台是如何架构的?
迪卡侬的数据平台采用Medallion架构,使用AWS S3存储Delta表,并通过MWAA管理工作流。
Polars的语法与Spark有什么相似之处?
Polars的语法与Spark相似,这使得团队能够更容易地将Spark作业迁移到Polars。
迪卡侬在使用Polars时有哪些实施限制?
迪卡侬决定仅在输入表小于50 GiB且不涉及复杂聚合的情况下实施Polars。
