
Climate planning has prioritized floods. Heat demands equal attention
McKinsey Insights & Publications
·

理解 KV Cache:Attention、P/D 分离与 vLLM 的页式显存管理
Steins;Lab
·
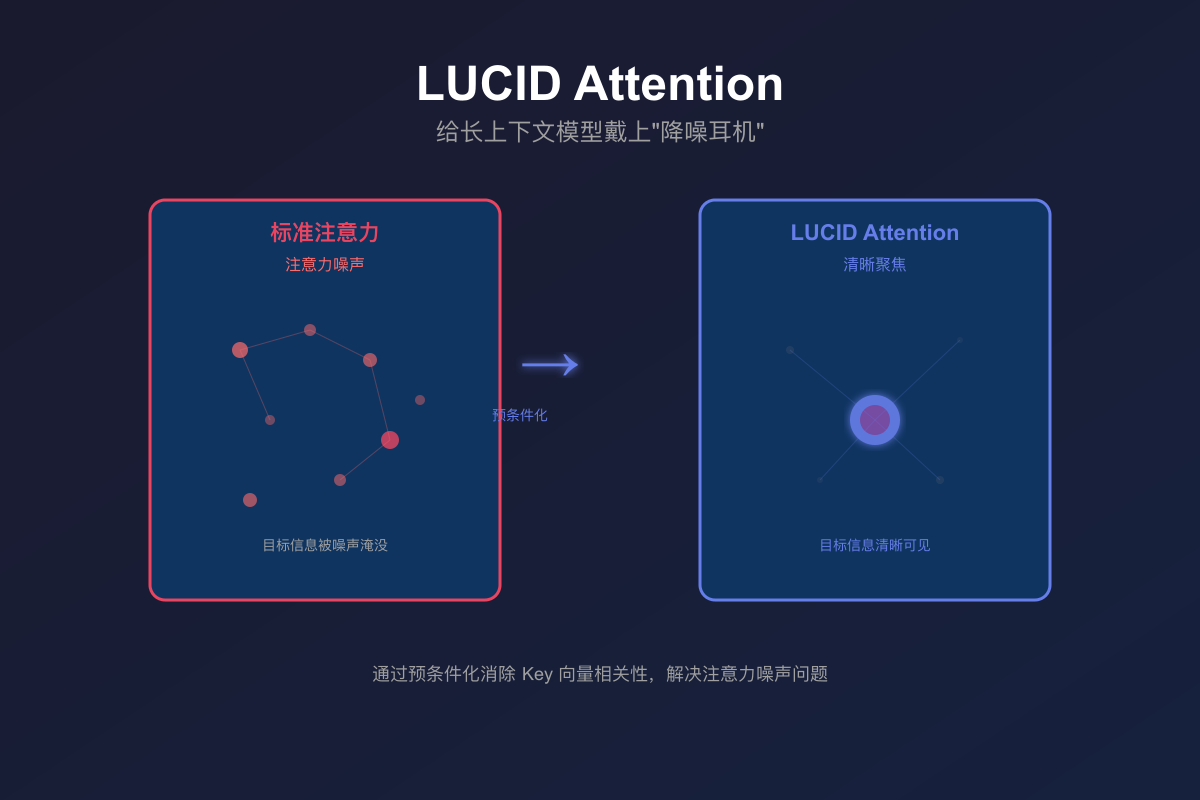
LUCID Attention:给长上下文模型戴上降噪耳机
Micropaper
·

