

本地无Gpu环境部署bge-reranker模型实现rerank - 乂墨EMO
博客园 - 乂墨EMO
·

智源开源多模态向量模型BGE-VL:多模态检索新突破
机器之心
·

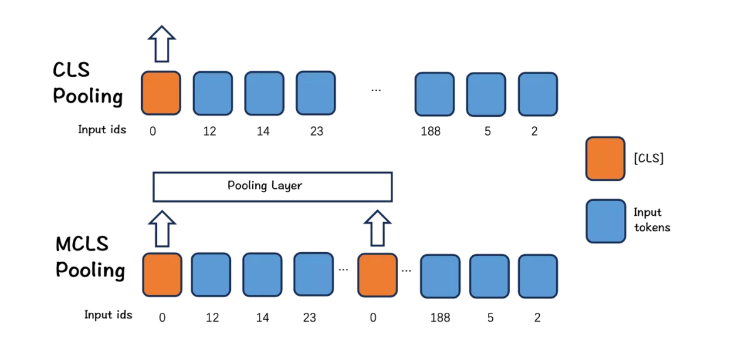
BGE M3-Embedding 模型介绍 - JadePeng
博客园 - JadePeng
·
