

简化自监督视觉:编码率正则化如何改变 DINO 和 DINOv2
实时互动网
·

向量搜索的复杂性:来自图像搜索和RAG项目的见解 - Noé Achache | 向量空间讲座
Qdrant - Vector Database
·
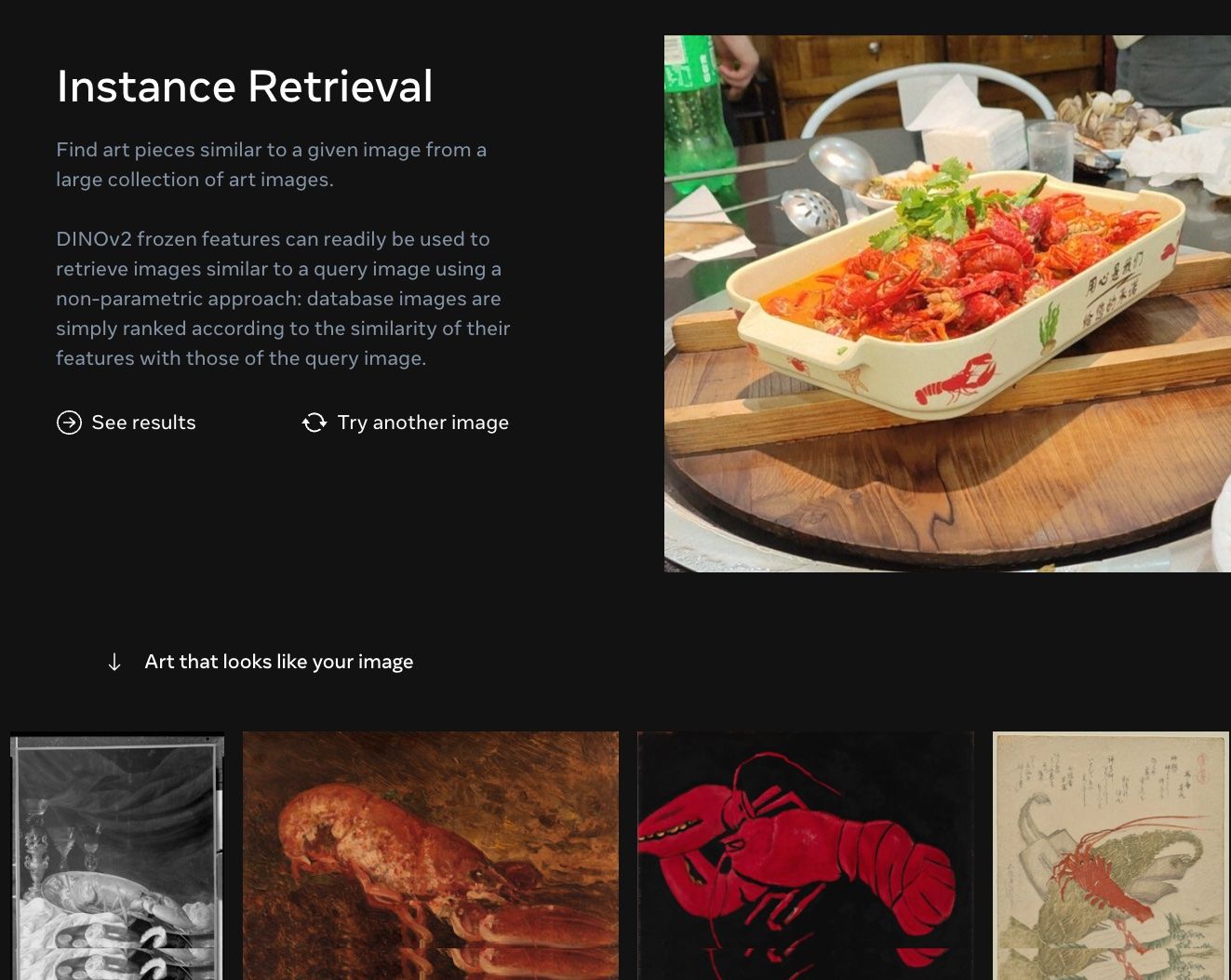
dinov2_retrieval:一个基于DINOv2 的图片检索应用
Yunfeng's Simple Blog
·
