DINO和DINOv2模型用于从未标记图像中学习特征,但训练复杂且不稳定。SimDINO和SimDINOv2通过引入编码率正则化项,简化了训练过程,提高了稳定性和效率,表现优于前者,适合视觉自监督学习。
文章讨论了对π0开源项目的期待与遗憾,分析了OpenVLA和CogACT的源码,重点介绍了动作预测模块的实现,包括ActionTokenizer类的功能和Diffusion Transformer的架构。通过对比不同模型,探讨如何改进VLA以接近π0的思路。
DINO是一种自监督学习方法,通过知识蒸馏提升视觉Transformer的特征质量。它动态构建教师网络,利用学生网络输出进行训练,优化图像特征学习。DINO采用多裁剪策略和温度softmax,提升模型性能。
本研究评估了DINOv2模型在复杂解剖结构下进行左心房分割的有效性,平均Dice系数为0.871,Jaccard指数为0.792,显示其在医学影像中的应用潜力。
本研究通过低秩适配(LoRA)技术改进鸟瞰图(BEV)表示,增强了其在环境变化和故障下的鲁棒性。实验结果表明,该方法在参数更少、训练更快的情况下,显著提升了BEV感知效果。
本文探讨深度学习在语义分割中的应用,结合CNN和CRF模型,通过引入上下文信息和高效训练方法提升分割准确度。研究表明,该方法在多个数据集上达到了先进水平,并提出新的自监督学习框架和数据驱动方法,显著提高了语义分割性能。
本研究评估了DINOv2模型在放射学中的应用,发现其在疾病分类和器官分割任务中表现优越。DINOv2在公共数据集上表现良好,适用于医学图像分类。此外,研究提出了DINO-IR多任务图像修复方法,利用稳健特征提升修复效果。DINOv2在少样本分割和异常检测中也展现出竞争力,推动了计算机视觉和数字岩石物理学的发展。
本文研究了深度学习医学成像应用中使用自然图像数据集进行迁移学习的方法,发现迁移学习对性能提升有限,简单轻量级模型可与ImageNet架构相当。同时探讨了迁移的权重尺度独立特性和对更高效模型探索的意义。
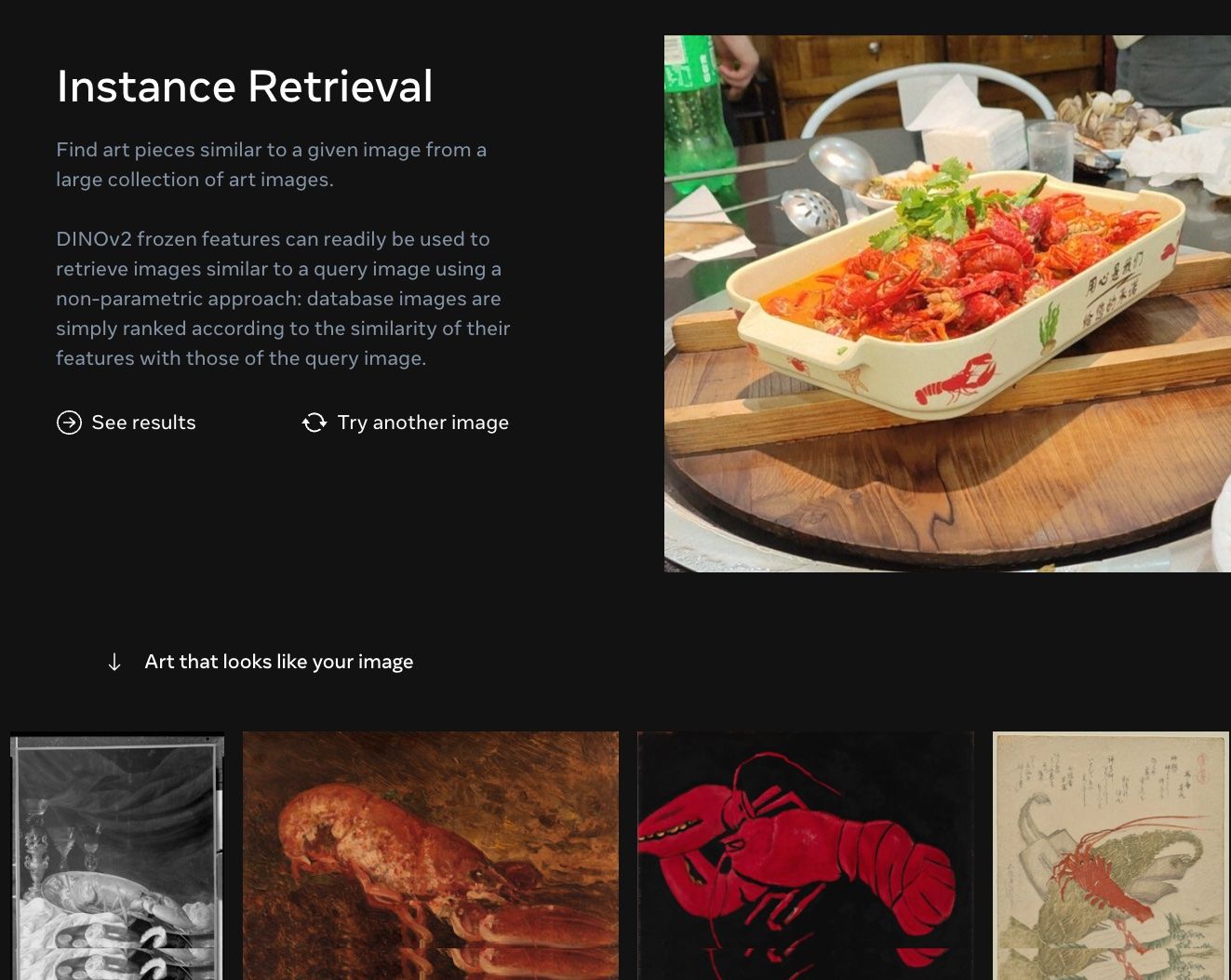
Meta发布了DINOv2视觉预训练模型,能够高效地从图像中提取特征。他们提供了一个在线演示,用户可以上传图像并检索相似的艺术作品。DINOv2模型的特征提取能力强大,能准确理解图像中的语义信息。dinov2_retrieval Python工具是为了使用DINOv2特征从测试数据集中检索相似图像而开发的。该工具可以使用pip进行安装,并具有各种自定义选项。作者反思了拥有有趣和多样化的数据库对于有意义的AI应用的重要性。
完成下面两步后,将自动完成登录并继续当前操作。