Irodori-TTS是由开发者Aratako于2026年发布的日语语音合成项目,具有高保真音质和零样本声音克隆能力。核心模型Irodori-TTS-500M-v3支持48 kHz专业音频输出,用户只需提供3-10秒的参考音频即可精准复刻目标音色,并通过Emoji注释调节情绪和语调。
字节推出了开源视频生成与编辑框架Bernini,强调“先理解再生成”。该框架利用多模态大模型进行语义理解,并通过扩散模型实现高质量渲染,解决视频编辑中的一致性和自然性问题。Bernini支持多种编辑选项,如天气、风格和焦点,能够处理复杂视觉效果,提高创作的可控性和稳定性。
本文介绍了Ψ0模型,该模型结合大规模人类视频数据与真实机器人数据,训练出一种用于类人机器人灵巧运动的视觉-语言动作模型,能够有效提取运动先验,实现复杂的全身控制。
本文介绍了一种新型机器人学习模型X-VLA,采用软提示技术以提升跨具身机器人学习的适应性和泛化能力。通过引入可学习的嵌入,X-VLA有效解决了不同硬件和任务环境下的异质性问题,增强了模型在多样化数据集上的表现。该模型在多个基准测试中表现优异,展现出在灵巧操作和适应新领域方面的强大能力。
本文回顾了作者创业11年的历程,并介绍了上海AI LAB发布的DualVLN模型。该模型结合视觉-语言导航推理与实时控制,采用双系统架构,分别负责高层推理和低层动作执行,提升了动态环境中的导航能力。实验结果表明,DualVLN在多种场景中表现优异,成功率高,导航误差低。
本文研究了扩散变换器(DiTs)在文本到图像生成中的效率,分析了架构选择和训练策略。结果表明,标准DiT在性能上与专门模型相当,但参数效率更高。通过层级参数共享策略,DiT-Air和DiT-Air-Lite在保持竞争力的同时,模型尺寸减少了66%。DiT-Air在GenEval和T2I CompBench上表现优异。
Crazy Time Live van Evolution – Waar je dit popul […]
MySQL是流行的关系型数据库管理系统,广泛应用于WEB开发。Linux是开源操作系统,Shell脚本用于简化管理。Docker用于开发和运行应用,Tomcat是轻量级Web服务器。Jenkins是持续集成工具,Redis和memcached是高效的数据库和缓存系统。Kubernetes在云计算运维中至关重要,帮助管理容器化应用。
Stort udvalg af spilleautomater og live casino – er htt […]
字节跳动的InfinityStar方法在视频生成方面超越了DiT,速度提升10倍,单GPU可在一分钟内生成5秒720p视频。其核心在于时空金字塔建模,结合静态与动态信息,提高了生成效率和质量。
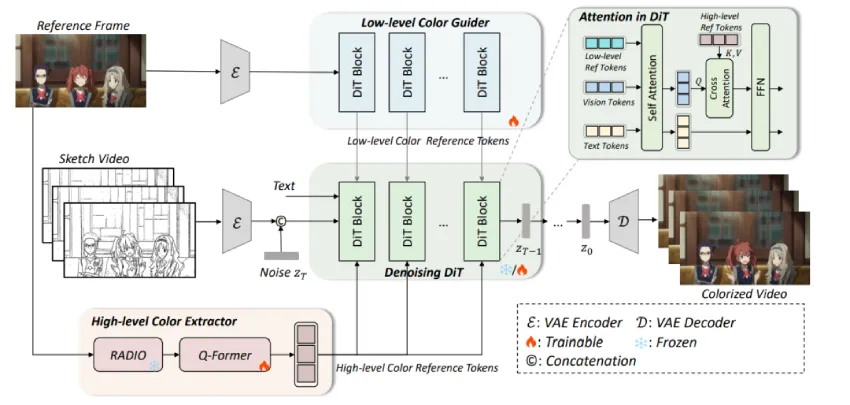
本文提出了一种新型动画上色模型ColorAnime,基于视频扩散模型,能够根据参考图像自动将草图序列转化为高质量彩色动画。该模型通过高低层次颜色提取器实现颜色一致性和细粒度控制,克服了现有方法在大幅运动场景中的不足,实验结果表明其在颜色准确性和视频质量方面表现优异。
本文探讨了大型行为模型(LBM)在波士顿动力人形Atlas中的应用,强调其在复杂任务中的表现。LBM通过多任务数据集训练,提升了机器人在动态环境中的自主互动能力。研究表明,LBM在微调新任务时仅需少量数据,并且在应对环境变化时表现更为稳健。尽管取得了一定进展,仍面临评估标准化和数据收集等挑战。
DiT模型受到质疑,网友认为其数学和形式上存在错误,甚至怀疑是否使用了Transformer。作者谢赛宁回应称,科学进步需要发现模型的不足,强调实证方法的重要性,并反驳质疑,指出Tread模型与DiT无关,且DiT在生成效果上仍具优势。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,帮助用户轻松获取所需数据。
普林斯顿大学与Meta合作推出LinGen框架,通过MATE模块将视频生成复杂度降低至线性,显著提升生成效率。LinGen在视频质量上优于DiT,生成速度最高可加速15倍,且适应性强,能处理更长的token序列。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,简化数据爬取流程。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
智象未来推出全球首个开放使用的DiT模型,依托商汤强大的AI基础设施,实现快速模型迭代。该模型高效、灵活、稳定,广泛应用于影视和教育领域,推动文生视频技术发展。
本文提出了一种新的混合专家模型(EC-DIT),通过优化专家选择路由以适应不同文本图像的复杂度。EC-DIT可扩展至970亿参数,显著提升训练收敛性和生成质量,并在文本对齐评估中获得71.68%的最佳GenEval分数。
完成下面两步后,将自动完成登录并继续当前操作。