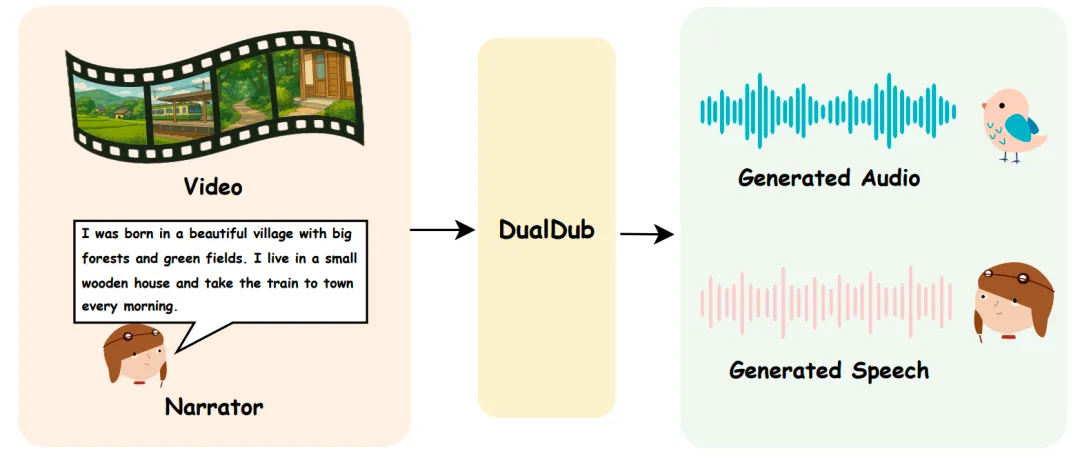
西工大音频语音与语言处理研究组提出的DualDub模型,旨在同时生成视频的背景音频和语音,解决了现有视频到音频模型忽视语音的问题。该模型通过多模态编码器和对齐模块,实现音频与语音的同步生成,并引入DualBench基准测试集,实验结果显示其在生成质量和时间同步性方面表现优异。
完成下面两步后,将自动完成登录并继续当前操作。