
DualDub:同时生成和谐的语音与背景音频,构建完整的视频音轨 | ACM MM 2025
内容提要
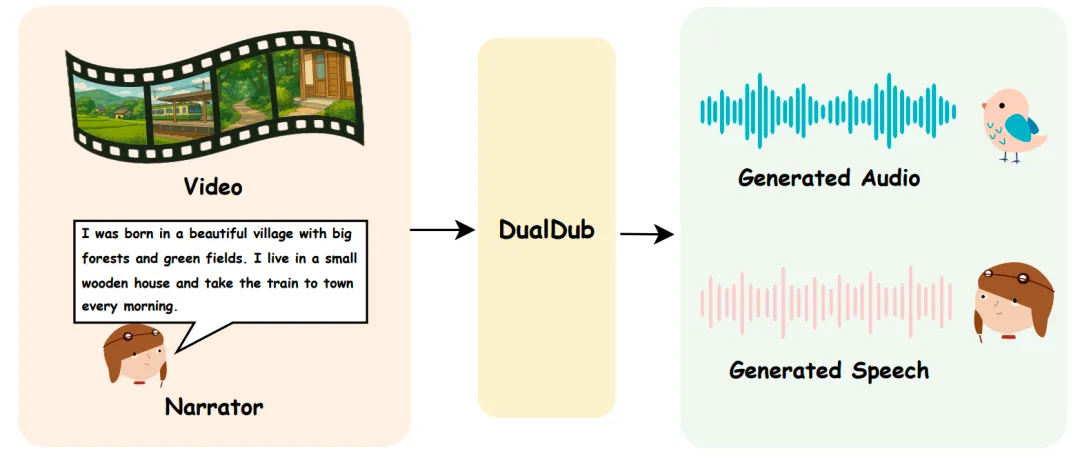
西工大音频语音与语言处理研究组提出的DualDub模型,旨在同时生成视频的背景音频和语音,解决了现有视频到音频模型忽视语音的问题。该模型通过多模态编码器和对齐模块,实现音频与语音的同步生成,并引入DualBench基准测试集,实验结果显示其在生成质量和时间同步性方面表现优异。
关键要点
-
西工大音频语音与语言处理研究组提出DualDub模型,旨在同时生成视频的背景音频和语音。
-
DualDub模型解决了现有视频到音频模型忽视语音的问题。
-
该模型通过多模态编码器和对齐模块,实现音频与语音的同步生成。
-
引入DualBench基准测试集,评估生成质量和时间同步性。
-
DualDub包含三个主要组件:多模态编码器、多模态对齐器和多模态语言模型。
-
多模态对齐模块结合因果注意力与非因果注意力机制,提升生成内容的时间同步性和声学和谐性。
-
提出课程学习策略,逐步构建模型的多模态能力以应对数据稀缺问题。
-
实验结果表明,DualDub在生成高质量、时间同步的音轨方面表现优异。
-
评估指标分为生成质量、音视频对齐度和音频-语音和谐度。
-
DualDub在Video-to-Audio和Video-to-SoundTrack任务上均表现良好,展示了其强大的语音生成能力。
延伸解读
DualDub模型的创新意义
DualDub模型通过同时生成背景音频和语音,填补了现有视频到音频模型在语音生成方面的空白。这一创新不仅提升了音轨的整体质量,还为视频内容创作者提供了更高效的音频生成工具,可能改变视频制作的工作流程。
多模态对齐的重要性
DualDub的多模态对齐模块结合因果与非因果注意力机制,显著提升了音频与语音的时间同步性和声学和谐性。这一技术的成功应用,意味着未来在多模态生成任务中,如何有效对齐不同模态的信息将成为关键挑战。
课程学习策略的优势
为应对数据稀缺问题,DualDub采用了课程学习策略,逐步提升模型的多模态能力。这种方法不仅有效利用了有限的数据资源,还避免了模型在训练过程中的灾难性遗忘,展示了在低资源条件下的训练潜力。
延伸问答
DualDub模型的主要功能是什么?
DualDub模型旨在同时生成视频的背景音频和语音,解决现有模型忽视语音的问题。
DualDub模型是如何实现音频与语音的同步生成的?
DualDub通过多模态编码器和对齐模块,实现音频与语音的同步生成。
DualBench基准测试集的作用是什么?
DualBench基准测试集用于评估DualDub在生成质量和时间同步性方面的表现。
DualDub模型的三个主要组件是什么?
DualDub包含多模态编码器、多模态对齐器和多模态语言模型三个主要组件。
课程学习策略在DualDub模型中的作用是什么?
课程学习策略帮助DualDub在数据稀缺的情况下逐步构建多模态能力。
DualDub在Video-to-Audio任务上的表现如何?
DualDub在Video-to-Audio任务上表现良好,能够生成高质量的音轨。
