ECCV 2024 Redux第三天结束,讨论了卫星与街景图像生成模型、3D场景压缩技术及细长管状结构分割方法。研究者们分享了创新成果与技术挑战,强调了计算机视觉领域的应用潜力。
本研究提出了一种几何解耦网络(GDNet),旨在从压缩深度源恢复高质量深度图。该方法有效处理局部细节与全局特征,显著提升了几何一致性和细节恢复能力,并在ECCV 2024 AIM挑战中获得一等奖。
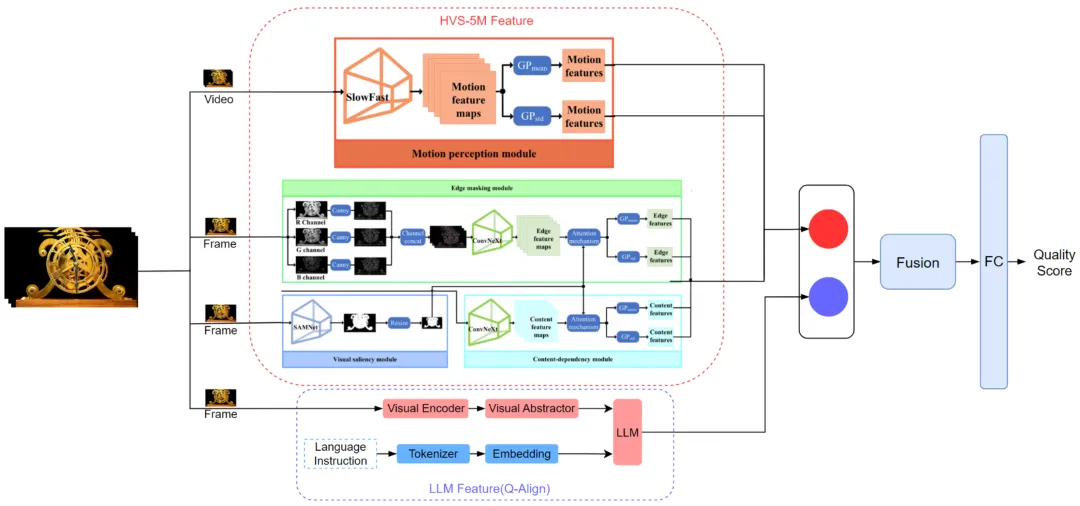
腾讯TVQA-C视频质量评估算法在ECCV 2024 AIM Workshop大赛中获冠军,未来将应用于腾讯云媒体处理产品,以提升媒体质量监控与分析能力。该算法通过优化模型结构和训练策略,准确评估视频质量,推动视频编码器研发和用户体验提升。
ECCV 2024 在米兰开幕,录用率创新低。哥伦比亚大学研究者凭借极简视觉系统获最佳论文奖,该系统用少量像素完成视觉任务,保护隐私且自供电。Meta 和波士顿大学的论文获最佳论文提名。Koenderink 奖授予 Microsoft COCO 数据集,强调物体与环境关系。Everingham 奖颁给 CelebA 数据集团队和 David Forsyth,表彰其对计算机视觉的贡献。
Meta和佐治亚理工的研究者提出了LEGO模型,该模型结合用户问题和场景照片生成第一视角动作图像,提升技能学习效率。通过微调大语言模型和扩散模型生成图像,LEGO在Ego4D和Epic-Kitchens数据集上表现出色,图像准确反映动作细节并保留背景信息,用户满意度高。研究证明了LEGO在多场景下的泛化能力,推动了动作图像生成领域的发展。
中国科学院自动化所和阿里云合作推出街景定位大模型AddressCLIP,通过一张照片实现街道级精度的定位。该模型基于CLIP构建,通过数据集构建和模型训练实现图像地理定位任务。AddressCLIP在定量和定性实验中表现优于其他方法。未来可应用于社交媒体个性化推荐和地理信息问答。
本文提出了FairDomain,首次系统性研究算法在域转移下的公平性。通过自注意力机制调整特征重要性,提高各种算法的公平性。同时,公开了第一个关注公平性的domain-shift数据集。广泛评估表明,FIA在所有域转移任务中显著增强了模型的公平性和性能。
完成下面两步后,将自动完成登录并继续当前操作。