


MAPFRE USA如何通过Amazon EMR无服务器技术现代化保险欺诈理赔
AWS Architecture Blog
·

从SSH到REST:Slack EMR数据管道的安全驱动现代化
Slack Engineering
·
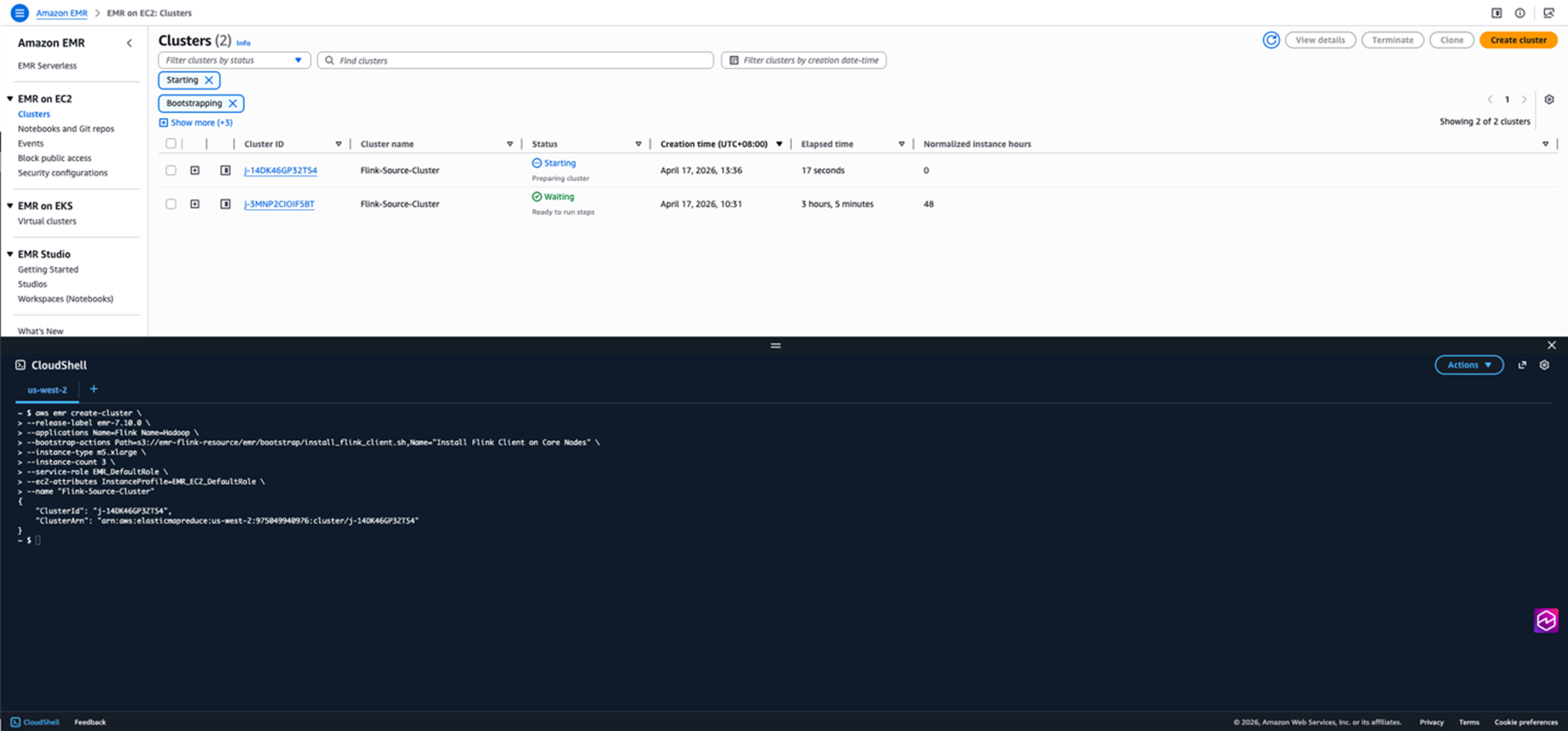
在AWS EMR Core节点部署Flink Client的实战指南
亚马逊AWS官方博客
·

使用 Kiro AI IDE 开发 基于Amazon EMR 的Flink 智能监控系统实践
亚马逊AWS官方博客
·
使用Amazon EMR Serverless Storage简化运维节省成本
亚马逊AWS官方博客
·
基于 Strands Agents 的 Amazon EMR Flink 智能监控系统
亚马逊AWS官方博客
·
EMR和S3的跨区域应急备份恢复方案之二:亿级数据文件批量筛选恢复
亚马逊AWS官方博客
·
Amazon EMR on EC2 Step提交作业及和MWAA集成最佳实践
亚马逊AWS官方博客
·
亚马逊云科技Flink计算引擎使用指南
亚马逊AWS官方博客
·
EMR和S3的跨区域应急备份恢复方案 之一:在存储成本与恢复时效之间取得平衡
亚马逊AWS官方博客
·
Amazon EMR 升级全指南(2025)
亚马逊AWS官方博客
·
基于开源工具构建 EMR 数据分析平台(五)EMR 最佳实践
亚马逊AWS官方博客
·
基于开源工具构建 EMR 数据分析平台(四)使用 Kyuubi 进行 Spark SQL 任务提交
亚马逊AWS官方博客
·
AWS Lake Formation 数据权限管控实践指南:从 EMR 集成到 BI 工具访问控制
亚马逊AWS官方博客
·
EMR Flink-Hudi 实时分析系统成本优化
亚马逊AWS官方博客
·

基于 Apache Kafka 和 AWS 构建端到端的无服务器流式 ETL 管道
亚马逊AWS官方博客
·
