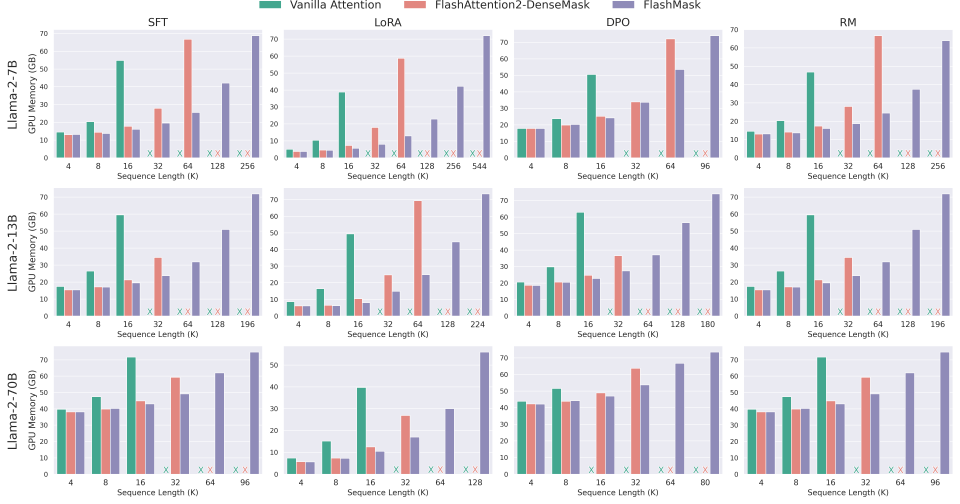
飞桨推出的FlashMask技术通过列式稀疏掩码表示方法,显著降低了Transformer大模型训练中的冗余计算和存储需求。与传统稠密掩码相比,FlashMask在训练速度上提升了1.65至3.22倍,支持更长序列的高效训练,且不影响模型精度。该技术适用于多种下游任务,推动了大语言模型的发展。
论文介绍了FlashMask,这是一种增强FlashAttention的高效掩码扩展。通过添加掩码功能,FlashMask在需要注意力掩码的任务中提高了性能。实验显示,它在图像分类和语言建模中表现出色,同时保持速度和内存效率。论文还讨论了其局限性,如对模型可解释性的影响,并建议在更多应用中探索其潜力。
完成下面两步后,将自动完成登录并继续当前操作。