
飞桨首创 FlashMask :加速大模型灵活注意力掩码计算,长序列训练的利器
内容提要
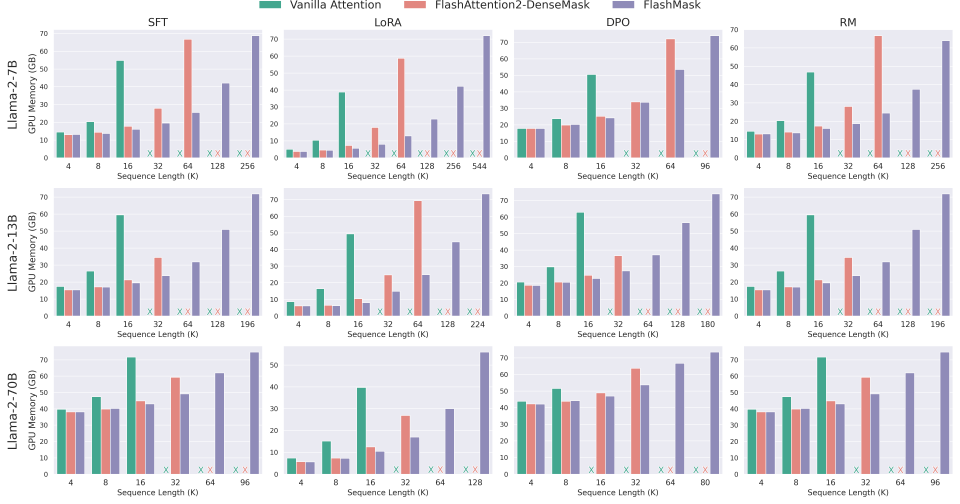
飞桨推出的FlashMask技术通过列式稀疏掩码表示方法,显著降低了Transformer大模型训练中的冗余计算和存储需求。与传统稠密掩码相比,FlashMask在训练速度上提升了1.65至3.22倍,支持更长序列的高效训练,且不影响模型精度。该技术适用于多种下游任务,推动了大语言模型的发展。
关键要点
-
FlashMask技术通过列式稀疏掩码表示方法,显著降低了Transformer大模型训练中的冗余计算和存储需求。
-
与传统稠密掩码相比,FlashMask在训练速度上提升了1.65至3.22倍,支持更长序列的高效训练,且不影响模型精度。
-
FlashMask适用于多种下游任务,包括SFT、LoRA、DPO和RM,推动了大语言模型的发展。
-
FlashMask通过跳过完全掩码块的计算,减少了计算开销,同时保持了算法的精度。
-
该技术支持单向和双向混合注意力掩码模式训练,能够灵活应用于多种场景。
延伸解读
FlashMask的技术优势
FlashMask通过列式稀疏掩码表示方法,显著降低了Transformer模型训练中的冗余计算和存储需求。这种创新不仅提升了训练速度,还支持更长序列的高效训练,适用于多种下游任务,推动了大语言模型的发展。
应用场景与灵活性
FlashMask支持多种注意力模式,包括因果掩码和文档掩码,能够灵活应用于不同的训练场景。这种灵活性使得FlashMask在处理复杂任务时,能够有效提升模型性能,尤其是在多模态数据处理和长序列训练中。
与传统方法的比较
与传统的稠密掩码方法相比,FlashMask在训练速度上提升了1.65至3.22倍,同时保持了模型的精度。这一显著的效率提升使得FlashMask成为大模型训练中的重要工具,尤其是在需要处理长序列的场景中。
延伸问答
FlashMask技术的主要创新是什么?
FlashMask技术的主要创新是采用列式稀疏掩码表示方法,显著降低了Transformer大模型训练中的冗余计算和存储需求。
FlashMask与传统稠密掩码相比有什么优势?
FlashMask在训练速度上提升了1.65至3.22倍,并支持更长序列的高效训练,且不影响模型精度。
FlashMask适用于哪些下游任务?
FlashMask适用于多种下游任务,包括SFT、LoRA、DPO和RM。
FlashMask如何减少计算开销?
FlashMask通过跳过完全掩码块的计算,减少了计算开销,同时保持了算法的精度。
FlashMask支持哪些注意力掩码模式?
FlashMask支持单向和双向混合注意力掩码模式训练,能够灵活应用于多种场景。
FlashMask在大语言模型训练中的表现如何?
FlashMask在大语言模型微调和对齐训练中表现优异,显著提升了训练速度和存储效率。
