近年来,我通过AI工具提升工作效率,特别是使用GPT-3.5后受益匪浅。随着Claude和DeepSeek等新模型的出现,我逐渐将它们应用于代码生成和文档撰写,体验到AI的强大能力。
本研究探讨了零-shot链式思维提示在日语中的有效性。比较GPT-3.5与GPT-4o-mini后发现,前者在大学数学和抽象代数领域表现提升,但在更先进模型中效果有所下降,为日语处理中的推理能力改进提供了新见解。
本研究分析了ChatGPT的政治偏见和个性特征,比较了GPT-3.5与GPT-4的表现。结果显示,两者均存在进步主义和自由主义偏见,但GPT-4的偏见有所减弱,且更擅长模仿政治观点。
该研究探讨了大型语言模型(如GPT-2和GPT-3.5)中的性别偏见,分析了生成文本中的性别化词汇和偏见叙述。研究发现这些模型在职业选择和回答问题时存在性别刻板印象,并提出了减少偏见的算法和框架,强调了文化对性别偏见的影响,建议加强对模型的公平性测试。
本文探讨了大型语言模型(LLMs)在医学问答中的应用,特别是GPT-3.5和Med-PaLM 2的表现。研究表明,这些模型在医学考试和阅读理解中达到了人类水平,能够生成高质量的医学解释,提升回答能力。此外,多语言模型在某些情况下优于单语模型,研究呼吁开发新的评估标准以支持可解释的医疗问答研究。
微软、麻省理工、普林斯顿大学和沃顿商学院的研究表明,使用GitHub Copilot能提高开发者生产力26%。特别是经验较少的开发者受益更多。实验在2022至2023年进行,使用的是基于GPT-3.5的Copilot版本。
OpenAI发布了GPT-4o mini,取代了GPT-3.5,价格更便宜且在多种场景下表现出低成本和低延迟的特点。GPT-4o mini在多项测试中超过了竞争对手的小模型,并与其他公司合作将其用于实际应用。此外,OpenAI还推出了GPT-4o实时语音模式。
本文探讨了大语言模型(如LSTM和Transformer)在序列概率评估中的低估现象,尤其是在低概率序列中更为明显。研究发现,模型对不规范序列的概率高估导致了这种差距。对GPT-3.5和GPT-4的评估显示,输出概率影响模型准确性,尤其在低概率情况下表现不佳。因此,建议在使用大语言模型时需谨慎,并将其视为独特系统。
机器翻译在质量上不断进步,但性别偏见问题依然严重。为此,研究者推出了GATE X-E语料库,包含多种语言的翻译及性别变体,并开发了基于GPT-3.5的性别重写解决方案。研究表明,多个翻译系统普遍存在性别偏见,呼吁对机器翻译进行性别去偏见的深入研究。
DuckDuckGo推出了私人AI聊天功能,用户可以匿名访问GPT-3.5等模型。该服务不存储聊天记录,AI提供商无法利用这些数据进行训练。DuckDuckGo通过替换用户IP地址保护隐私,并与AI提供商达成协议,确保聊天记录在30天内删除。该功能免费使用,未来可能推出付费计划。
本研究探讨了GPT-3.5和GPT-4模型在教育中的应用,特别是在自动评分和个性化反馈方面。研究表明,GPT-3.5在评分准确性上优于BERT模型,并能生成高质量反馈。GPT-4在教师与学生的对话中表现出色,但在识别真诚赞扬方面存在不足。未来研究将集中于提升提示工程和评估模型的教学能力。
本研究探讨了多语言模型在数字推理中的能力,发现FlanT5和GPT-3.5在此方面表现优异。研究提出了一种新方法,通过锚定数字来提升语言模型的数字推理能力,实验结果显示显著改善。
ChatGPT API已停用,现称为GPT-3.5 Turbo API。所有付费用户可使用GPT-4。OpenAI API已推出,建议用户转向Chat Completions API。
GPT-3.5适用于使用RAG方法构建本地知识库的大多数场景,但GPT-4增强了其能力,在问题提取、排序和摘要等任务中提供更好的结果。GPT-4的更大知识库还允许提供更全面的回答。因此,虽然GPT-3.5可以处理RAG,但GPT-4表现更好,而不仅仅是过度的投入。
本研究探讨了大型语言模型(LLMs)在逻辑推理和谬误识别方面的能力,发现GPT-3.5和GPT-4在面对逻辑谬误时容易被说服。通过构建新的数据集(LFUD)评估LLMs的逻辑谬误理解能力,结果显示其在复杂推理任务中仍存在不足。研究提出了多种提升LLMs逻辑推理能力的策略,并强调了公平性在LLMs应用中的重要性。
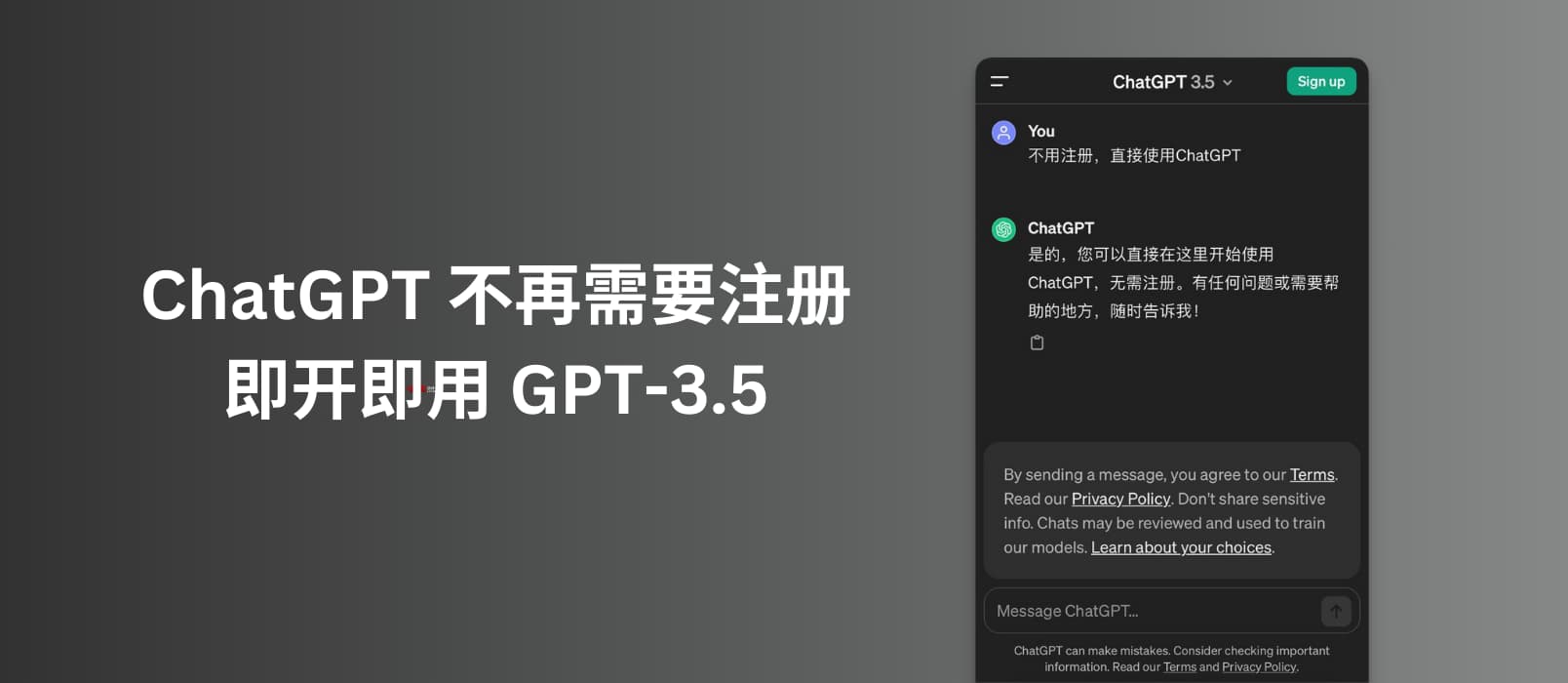
OpenAI宣布用户无需注册登录OpenAI账号即可使用ChatGPT,但只能使用GPT-3.5。Google Chrome团队提出了针对cookie劫持问题的DBSC标准。雅虎收购了资讯app Artifact,主要是为了获取其在内容分类和推荐系统上的技术。iOS 18的设备兼容性与iOS 17保持一致,但iPadOS 18不再支持某些iPad型号。
ChatGPT最近更新,无需注册账号,即开即用直接使用GPT-3.5。网页版ChatGPT已不需要注册,可立即开始提问。GPT-4仍需注册和付费使用。
斯坦福大学教授吴恩达表示,基于GPT-3.5构建的智能体作业流在实际应用中表现优于GPT-4。智能体作业流包括反思、东西运用、规划和多智能体协作四种形式。反思形式通过多次提示LLM来逐步提升输出质量。智能体作业流将推动人工智能的巨大进步。
本文评估了大型语言模型(LLMs)在法律领域的应用,特别是在法律推理和起草方面的能力。研究表明,GPT-3.5在法律起草中表现良好,但推理能力较弱,无法完全替代律师。同时,通过对阿拉伯法律分析和机器翻译的研究,强调了LLMs在处理专业法律术语方面的潜力,并呼吁改进评估方法。
大型语言模型(LLM)在解决物理和数学问题方面展现出潜力。研究表明,GPT-3.5能以零样本学习解决49.3%的初中物理问题,而GPT-4在医学物理学考试中表现优于其他模型。尽管存在逻辑错误和误导性答案的挑战,LLM在科学领域的应用仍具前景,尤其是在提高准确性和可靠性方面。
完成下面两步后,将自动完成登录并继续当前操作。


/cdn.vox-cdn.com/uploads/chorus_asset/file/23932932/acastro_STK117__02.jpg)