


NVIDIA H100的CUDA编程
freeCodeCamp.org
·
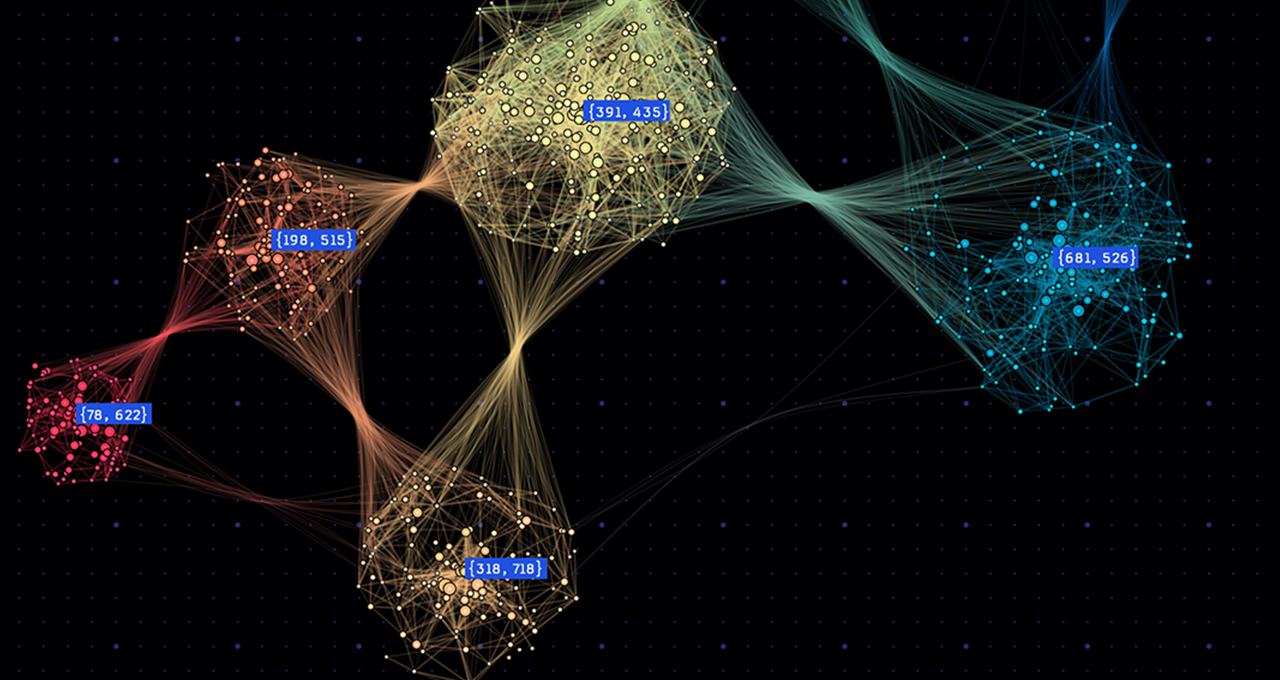
NVIDIA H100 GPU在CoreWeave的AI云平台上实现Graph500基准测试的破纪录表现
NVIDIA Blog
·

.png)
在欧盟推出由NVIDIA HGX H100加速的GPU Droplets
The DigitalOcean Blog
·
硅谷惊变:12万张H100的挽歌
宝玉的分享
·


AMD的未来
the singularity is nearer
·
