
HDFS DataNode 3.3.1 后优化详解
小令童鞋
·
3.3.1-3.4.1兼容性分析
小令童鞋
·
/filters:no_upscale()/news/2026/03/uber-scaled-data-replication/en/resources/1hivesyncjob-1771726530169.jpeg)
优步的混合云数据:工程师如何解决极大规模复制挑战
InfoQ
·

站在巨人的肩膀上:支撑现代人工智能的传统基础设施
云原生
·

如何在Python中使用ORC文件格式 - 带示例的指南
freeCodeCamp.org
·

从零开始大数据
Sekyoro的博客小屋
·
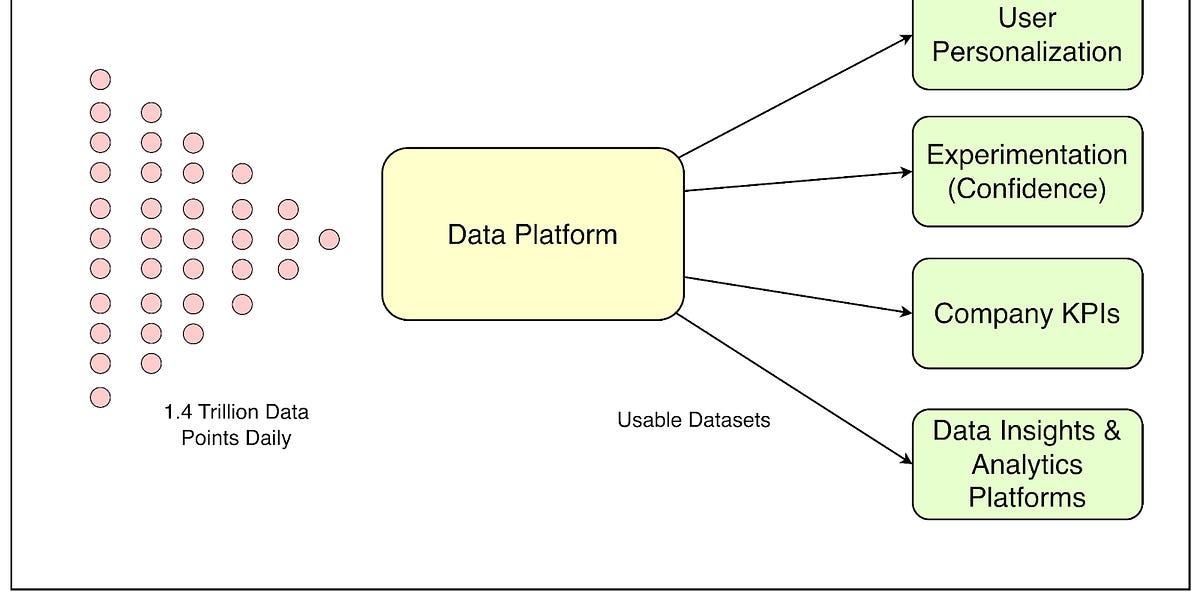
Spotify如何构建其数据平台以理解14万亿数据点
ByteByteGo Newsletter
·

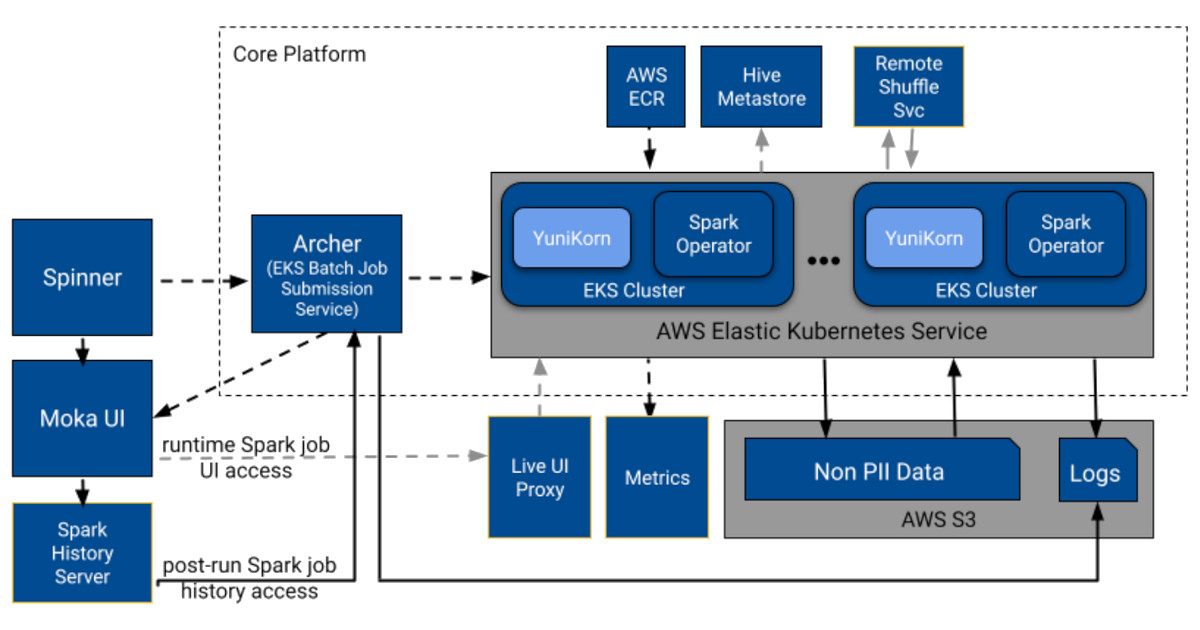
基于大模型和Spark的B站数据分析
厦大数据库实验室博客
·



大数据处理 - 案例研究 4 (Hadoop)
DEV Community
·


Hadoop的核心组件HDFS和MapReduce是如何运作的?
DEV Community
·
