本文介绍了Git中的引用(ref)及其磁盘表示,包括普通引用、符号引用和HEAD的概念。引用是指向对象ID的命名指针,分为松散引用和打包引用。HEAD指向当前检出位置,在detached HEAD状态下直接使用SHA。还讨论了轻量标签与附注标签的区别,以及如何使用git pack-refs合并引用以提高效率。
故事围绕拓巳的内心挣扎展开,他渴望死亡却又害怕死亡,反复经历自杀幻想。面对七海的存在,他感到困惑与绝望,认为自己是妄想的产物,最终在痛苦中寻求解脱,渴望被他人解放。
在《混沌之脑》中,西条拓巳在崩坏的城市中体验到恐惧与孤独,卷入“新世代疯狂”事件。故事探讨存在的意义、孤独感以及对现实与虚拟的逃避。拓巳的内心挣扎与妄想交织,最终发现自己与事件的关联,面临生死考验。
多头注意力机制的核心在于独立计算不同的注意力分布,而非简单平均。理解位置限制和计算复杂度是后续研究的重点。
本文分析了命令“yes | head”的执行过程。通过管道,yes不断输出“y”,而head只读取前10行。head完成后关闭读端,yes收到SIGPIPE信号而终止。文章探讨了Shell、内核和信号层的协作机制,体现了Unix设计哲学:简单组件通过管道高效协作。
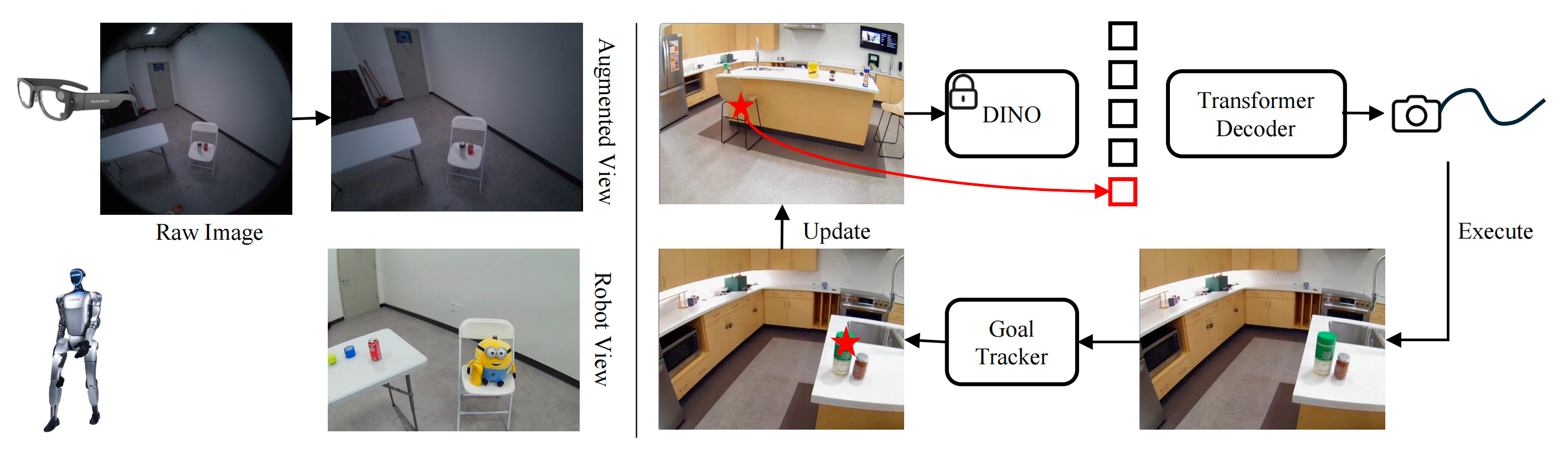
HEAD是一种人形机器人手眼自主递送系统,结合导航、运动与触达任务。通过模块化方法,利用人类数据训练机器人在复杂环境中高效完成目标操作,成功率达到71%。未来可扩展至更复杂的抓取任务。
PostgreSQL Conference Europe 2025 in Riga has officially come to an end — and what remains are the impressions, emotions, moments, and the incredible vibe that remind me why we do what we do. ...
Sharpen your problem-solving skills the McKinsey way, with our weekly crossword. Each puzzle is created with the McKinsey audience in mind, and includes a subtle (and sometimes not-so-subtle)...
在 Git 的 Detached HEAD 状态下,无法直接推送修改。建议创建临时分支以保存修改,并强制更新 main 分支后再推送。使用 --force-with-lease 可以避免覆盖他人提交。掌握此流程能提高 Git 使用效率。
本研究通过引入不确定性量化模块,显著提升了大语言模型对不确定性的捕捉能力,增强了幻觉检测性能和可靠性评估。
欢迎来到#100DaysOfLinux挑战第26天!今天我们将学习Linux命令行工具,包括grep、find、head、tail和wc。我们将创建一个示例文件,并完成四个挑战:使用grep查找特定行,使用find定位文件,使用head和tail查看文件的开头和结尾,最后使用wc统计行数和字数。选择三个挑战进行尝试并分享体验!
本研究提出双头优化(DHO)框架,旨在解决资源有限环境中视觉语言模型(VLMs)的计算复杂性和训练成本问题。DHO通过独立学习标记数据和教师预测,显著提升特征学习效率,并在多个领域和数据集上超越传统基线。
在红帽企业Linux 9中,命令行是管理文件的利器。find命令用于查找文件,head显示文件的前几行,tail展示文件的末尾内容,wc用于统计字数和行数。这些命令的组合使用可以高效管理系统,使学习Linux变得轻松有趣。
本研究提出了一种新的知识蒸馏方法——头尾关注的KL散度(HTA-KL),旨在缩小脉冲神经网络(SNN)与人工神经网络(ANN)之间的性能差距。该方法通过动态区分高低概率区域并分配适应性权重,提升知识转移的平衡性,最终在多个数据集上表现优于现有方法。
本研究提出一种新方法,使Nao机器人实时模仿人类的头部动作、眨眼和情感表达,结合MediaPipe和DeepFace技术,提高了精确性,尤其对自闭症儿童的沟通改善具有重要意义。
本研究提出了一种SHeaP方法,通过自监督学习和高斯渲染技术,实现了从单幅图像和视频中实时重建人头三维模型。该方法在中立和非中立表情的几何评估中超越了现有技术,并在情感分类任务中表现出优势。
本研究提出了一种量子退火多头注意力机制(QAMA),旨在解决经典注意力机制在大规模语言模型中的内存和能耗问题。QAMA通过二次无约束二进制优化模型实现与经典架构的兼容,显著降低能耗并保持实时响应,展示了量子计算与深度学习结合的潜力。
本研究提出了一种多头自适应图卷积网络,用于低光照环境下的稀疏点云人类活动识别。该方法通过动态调整卷积核,提高了识别的准确性和效率,实验结果在基准数据集上表现优异,具有实用价值。
本研究提出了一种名为SeLIP的对比学习框架,旨在解决医学图像分析中的标注数据不足问题。通过结合图像和放射学发现,增强了对比学习。实验结果表明,该模型在图像-文本检索、分类和图像分割等任务中表现优异,强调了文本相似性在医学图像基础模型构建中的重要性。
本研究提出了DiffusionTalker,一种通过个性化引导蒸馏实现高效紧凑的语音驱动3D交谈头的方法。该方法显著提高了动画生成的速度和精确度,模型存储需求减少至86.4%,效果超过现有技术,具有广泛应用前景。
完成下面两步后,将自动完成登录并继续当前操作。