
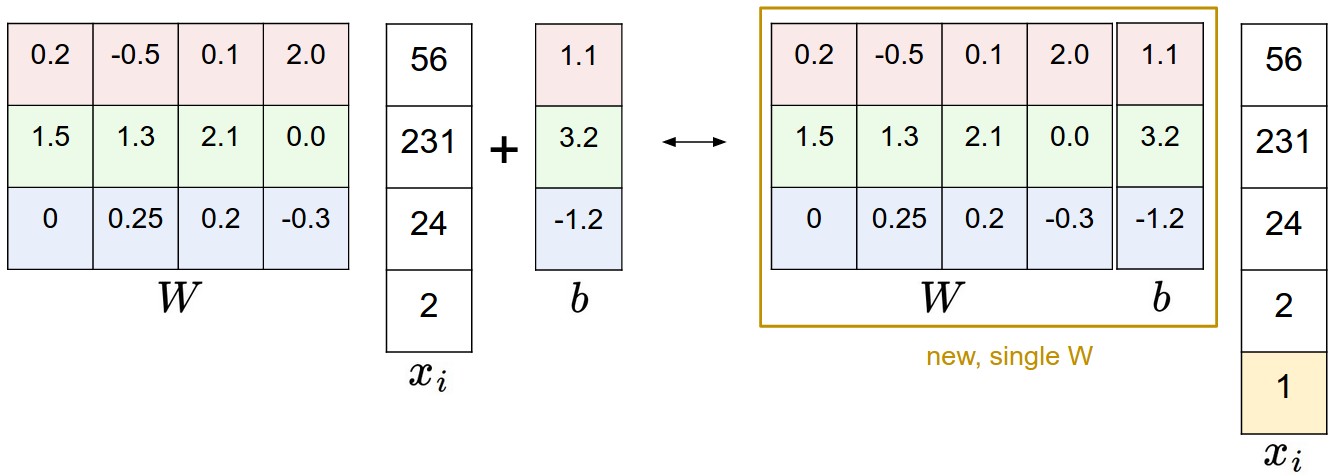
CS231n 讲义 II:线性分类器
Louis Aeilot's Blog
·

我们尝试了五种缺失数据插补方法:最简单的方法赢了(某种程度上)
KDnuggets
·
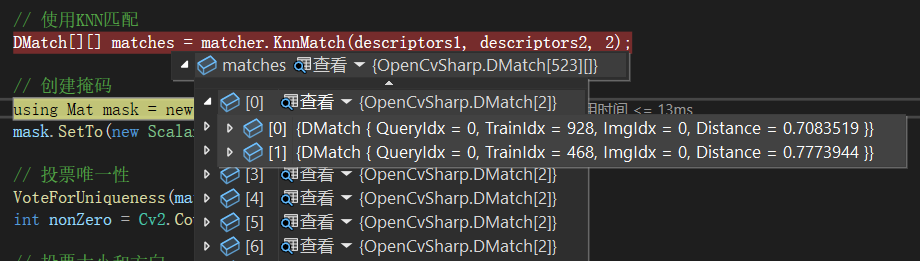
OpenCVSharp:在实际应用中使用 KAZE 算法进行特征匹配
dotNET跨平台
·

机器学习纪事:第一天 理解KNN与鸢尾花数据集
DEV Community
·

明天会下雨吗?
DEV Community
·

在商业环境中使用K-近邻算法(KNN)
DEV Community
·

aNN与kNN:理解它们在向量搜索中的差异与角色
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
恶意软件数据依赖图特征的 kNN 分类
BriefGPT - AI 论文速递
·
