
CS231n 讲义 II:线性分类器
内容提要
KNN算法存在缺陷,需要更强大的方法。新方法使用评分函数将图像像素映射为类别分数,并通过损失函数量化预测分数与真实标签的差异。我们采用多类支持向量机(SVM)损失,结合正则化,优化模型以提高泛化能力。Softmax分类器将分数视为未归一化的对数概率,并使用交叉熵损失进行优化。
关键要点
-
KNN算法存在缺陷,需要更强大的方法。
-
新方法包括评分函数和损失函数。
-
评分函数将图像像素映射为类别分数。
-
损失函数量化预测分数与真实标签的差异。
-
采用多类支持向量机(SVM)损失,结合正则化以优化模型。
-
Softmax分类器将分数视为未归一化的对数概率。
-
使用交叉熵损失进行优化。
-
线性分类器通过线性映射计算分数。
-
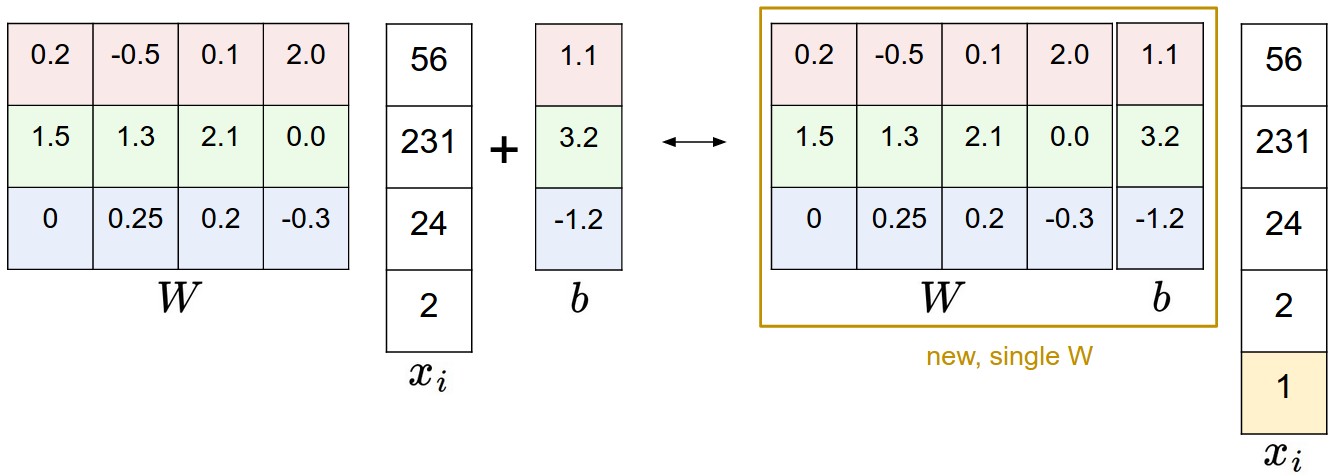
偏置技巧通过扩展输入向量来简化参数设置。
-
图像数据预处理包括特征归一化。
-
多类SVM损失函数通过最大化正确类分数与错误类分数的差异来工作。
-
正则化通过惩罚大权重来提高模型的泛化能力。
-
设置超参数Delta为1.0是安全的。
-
Softmax分类器使用交叉熵损失来优化概率分布。
-
信息论视角下,交叉熵最小化等同于最小化KL散度。
-
数值稳定性通过归一化技巧来处理大数值。
-
SVM与Softmax的主要区别在于损失函数的定义和目标。
-
SVM关注于类分数的边际,而Softmax关注于类概率的归一化。
延伸解读
KNN算法的局限性
KNN算法在处理高维数据时容易受到维度诅咒的影响,导致分类性能下降。相比之下,采用评分函数和损失函数的新方法能够更有效地处理复杂数据,提升分类准确性。
SVM与Softmax的比较
SVM和Softmax分类器在损失函数的定义上存在显著差异。SVM关注于类分数的边际,而Softmax则将分数视为概率分布。理解这两者的不同有助于选择合适的模型以满足特定任务的需求。
正则化的重要性
正则化在模型训练中起着关键作用,通过惩罚大权重来提高模型的泛化能力。这可以有效防止过拟合,确保模型在未见数据上的表现更为稳健。
延伸问答
KNN算法的缺陷是什么?
KNN算法存在缺陷,需要更强大的方法来提高分类性能。
什么是评分函数,它的作用是什么?
评分函数将图像像素映射为类别分数,用于计算每个类别的置信度。
多类支持向量机(SVM)损失函数是如何工作的?
多类SVM损失函数通过最大化正确类分数与错误类分数的差异来工作。
正则化在模型优化中有什么作用?
正则化通过惩罚大权重来提高模型的泛化能力,防止过拟合。
Softmax分类器与SVM的主要区别是什么?
SVM关注于类分数的边际,而Softmax关注于类概率的归一化。
交叉熵损失在Softmax分类器中如何应用?
交叉熵损失用于优化Softmax分类器的概率分布,使正确类的概率接近1。
