

EpiCache:用于长对话问答的情节KV缓存管理
Apple Machine Learning Research
·

理解 KV Cache:Attention、P/D 分离与 vLLM 的页式显存管理
Steins;Lab
·

使用TurboQuant的高效KV压缩
MachineLearningMastery.com
·

Rockraft:基于 OpenRaft 与 RocksDB 的强一致 KV 存储框架
codedump的网络日志
·

从提示到预测:理解大型语言模型中的预填充、解码和KV缓存
MachineLearningMastery.com
·
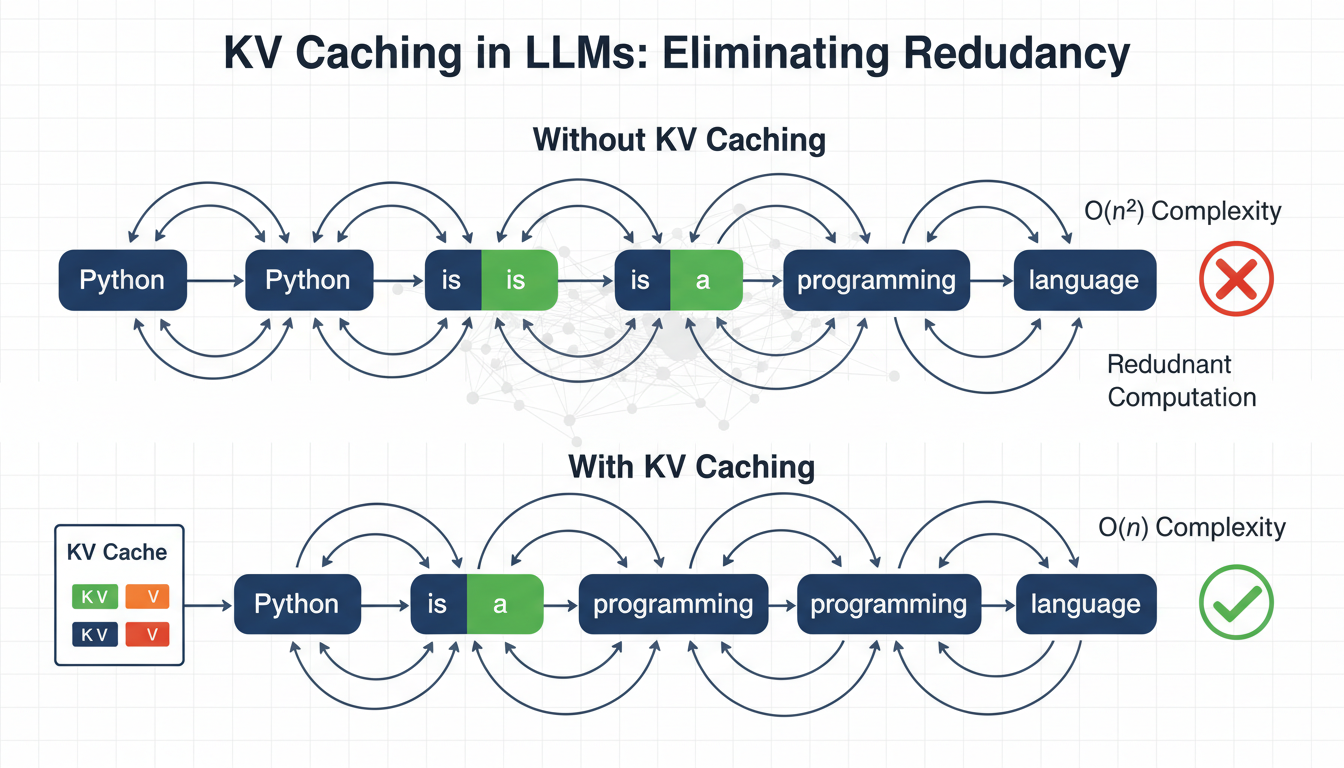
LLMs中的KV缓存:开发者指南
MachineLearningMastery.com
·
vLLM新KV卸载连接器内部揭秘:智能内存传输以最大化推理吞吐量
vLLM Blog
·

推理的物理学 – 深入探讨KV缓存和提示缓存
Shadow Walker 松烟阁
·

QuantSpec:基于分层量化KV缓存的自我推测解码
Apple Machine Learning Research
·

基于 Amazon SageMaker 有状态路由优化大规模推理集群下的 KV Cache 复用方案
亚马逊AWS官方博客
·
