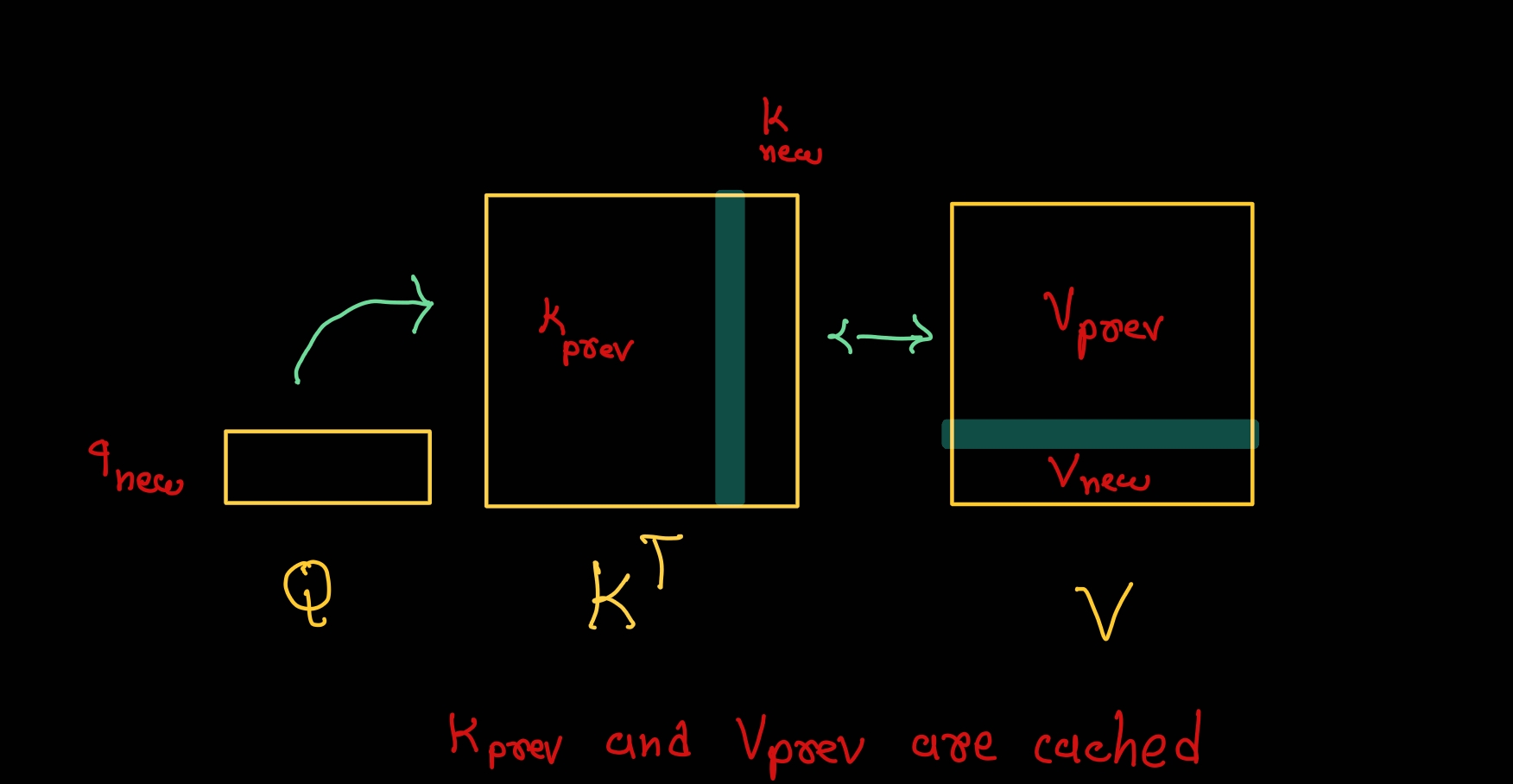
Llama-70B模型在处理128K token请求时,KV Cache占用429GB显存,成为推理成本的主要因素。通过TurboQuant、PD拆分和LMCache等技术,可以将长上下文推理成本降低4到40倍。这些技术的应用将显著提升效率,改善产品体验,推动LLM的广泛使用。
Deepseek-R1是首个具推理能力的开源模型,兼具速度和成本效益。用户可在Databricks上下载和部署Llama-70B及Llama-8B模型,享受安全性和性能优化。该模型支持扩展思维链,适合数学和编程任务,鼓励用户探索新用例并提供反馈。
完成下面两步后,将自动完成登录并继续当前操作。