
跑大模型,最贵的不是 GPU,是这个东西
内容提要
Llama-70B模型在处理128K token请求时,KV Cache占用429GB显存,成为推理成本的主要因素。通过TurboQuant、PD拆分和LMCache等技术,可以将长上下文推理成本降低4到40倍。这些技术的应用将显著提升效率,改善产品体验,推动LLM的广泛使用。
关键要点
-
Llama-70B模型在处理128K token请求时,KV Cache占用429GB显存,成为推理成本的主要因素。
-
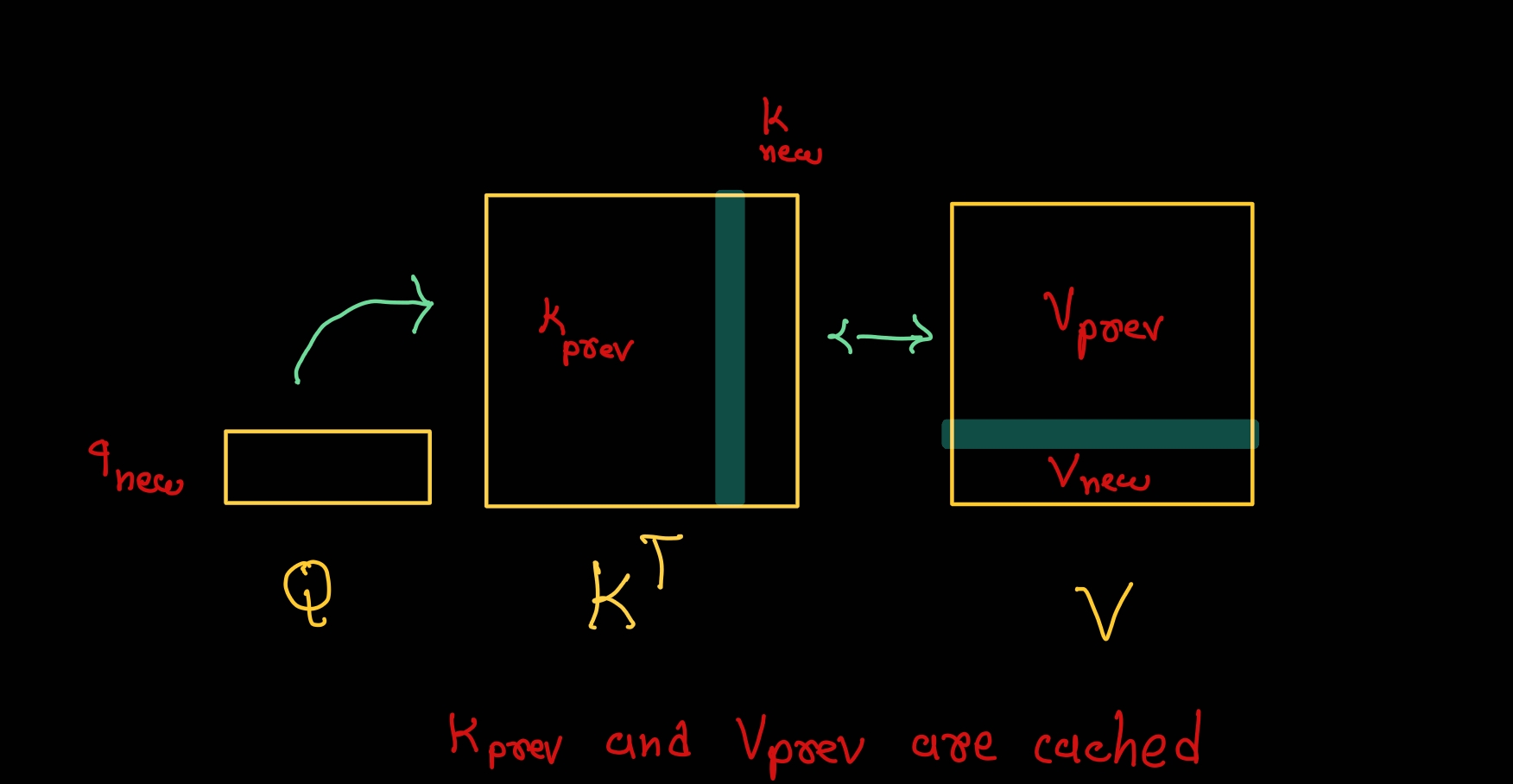
KV Cache的大小与序列长度成线性关系,序列越长,Cache越大。
-
TurboQuant技术可以将KV Cache压缩6倍,显著降低内存占用,Llama-70B的KV Cache从429GB压缩到约71GB。
-
PD拆分技术将推理过程分为Prefill和Decode两个阶段,分别在不同机器上运行,提高吞吐量并降低成本。
-
LMCache技术允许复用KV Cache,减少重复计算,提高多轮对话和RAG场景的吞吐量。
-
三种技术结合使用,可以将长上下文推理成本降低4到40倍,具体效果取决于场景的重复前缀数量。
-
对于短上下文和高并发场景,优先使用PD拆分;对于长上下文和成本敏感的场景,TurboQuant和LMCache是关键。
-
推理感知KV压缩是一种新兴的研究方向,能够根据不同token的重要性动态分配精度,潜在地降低内存占用。
延伸解读
KV Cache的重要性
在LLM推理中,KV Cache的大小直接影响显存需求和推理成本。随着序列长度的增加,KV Cache的占用量呈线性增长,这使得长上下文请求的处理变得更加昂贵。理解KV Cache的工作原理有助于优化模型的使用和资源配置。
技术组合的优势
TurboQuant、PD拆分和LMCache三种技术的结合使用,可以显著降低长上下文推理的成本。具体效果取决于场景的重复前缀数量,合理选择技术组合能够在不同应用场景中实现最佳性能,提升用户体验。
未来研究方向
推理感知KV压缩是一种新兴的研究方向,能够根据不同token的重要性动态分配精度。这种方法有潜力在未来进一步降低内存占用,提升推理效率,值得关注和探索。
延伸问答
Llama-70B模型的KV Cache占用多少显存?
Llama-70B模型在处理128K token请求时,KV Cache占用429GB显存。
TurboQuant技术如何降低KV Cache的内存占用?
TurboQuant技术可以将KV Cache压缩6倍,将Llama-70B的KV Cache从429GB压缩到约71GB。
PD拆分技术的主要功能是什么?
PD拆分技术将推理过程分为Prefill和Decode两个阶段,分别在不同机器上运行,提高吞吐量并降低成本。
LMCache技术如何提高多轮对话的吞吐量?
LMCache技术允许复用KV Cache,减少重复计算,从而在多轮对话场景中提升吞吐量。
如何选择适合的技术组合以降低推理成本?
对于短上下文和高并发场景,优先使用PD拆分;对于长上下文和成本敏感的场景,TurboQuant和LMCache是关键。
推理感知KV压缩是什么?
推理感知KV压缩是一种根据不同token的重要性动态分配精度的技术,能够潜在地降低内存占用。
