



大语言模型推理三难问题:吞吐量、延迟与成本
The DigitalOcean Blog
·

将 Florence-2 部署到 Inferentia2 的实战指南
亚马逊AWS官方博客
·
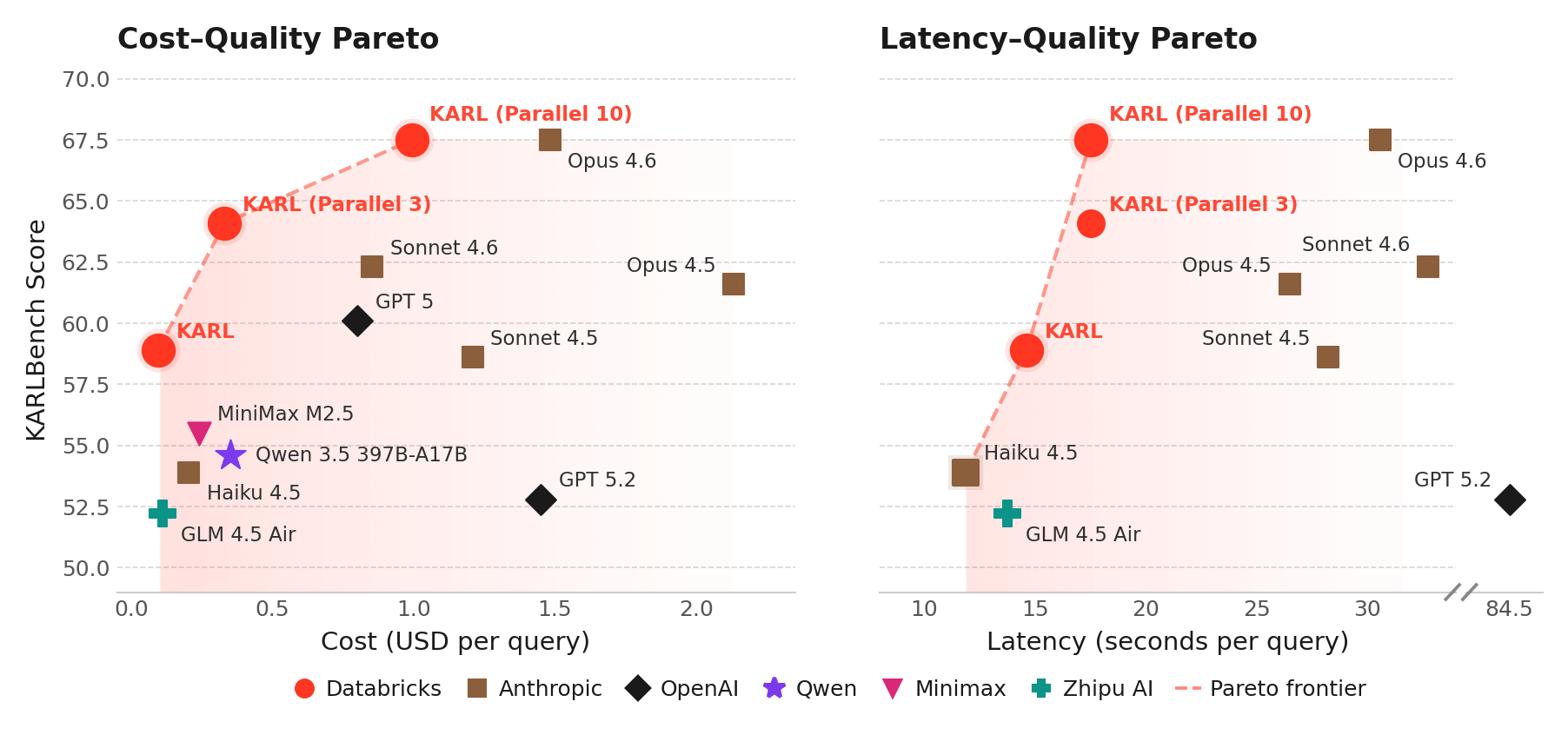
认识KARL:一个更快的企业知识代理,基于定制的强化学习
Databricks
·

领先的推理提供商通过NVIDIA Blackwell上的开源模型将AI成本降低至10倍
NVIDIA Blog
·

如何优化机器学习推理成本和性能
Redis Blog
·

浪潮信息元脑HC1000实现推理成本首次击破1元/每百万token
全球TMT-美通国际
·

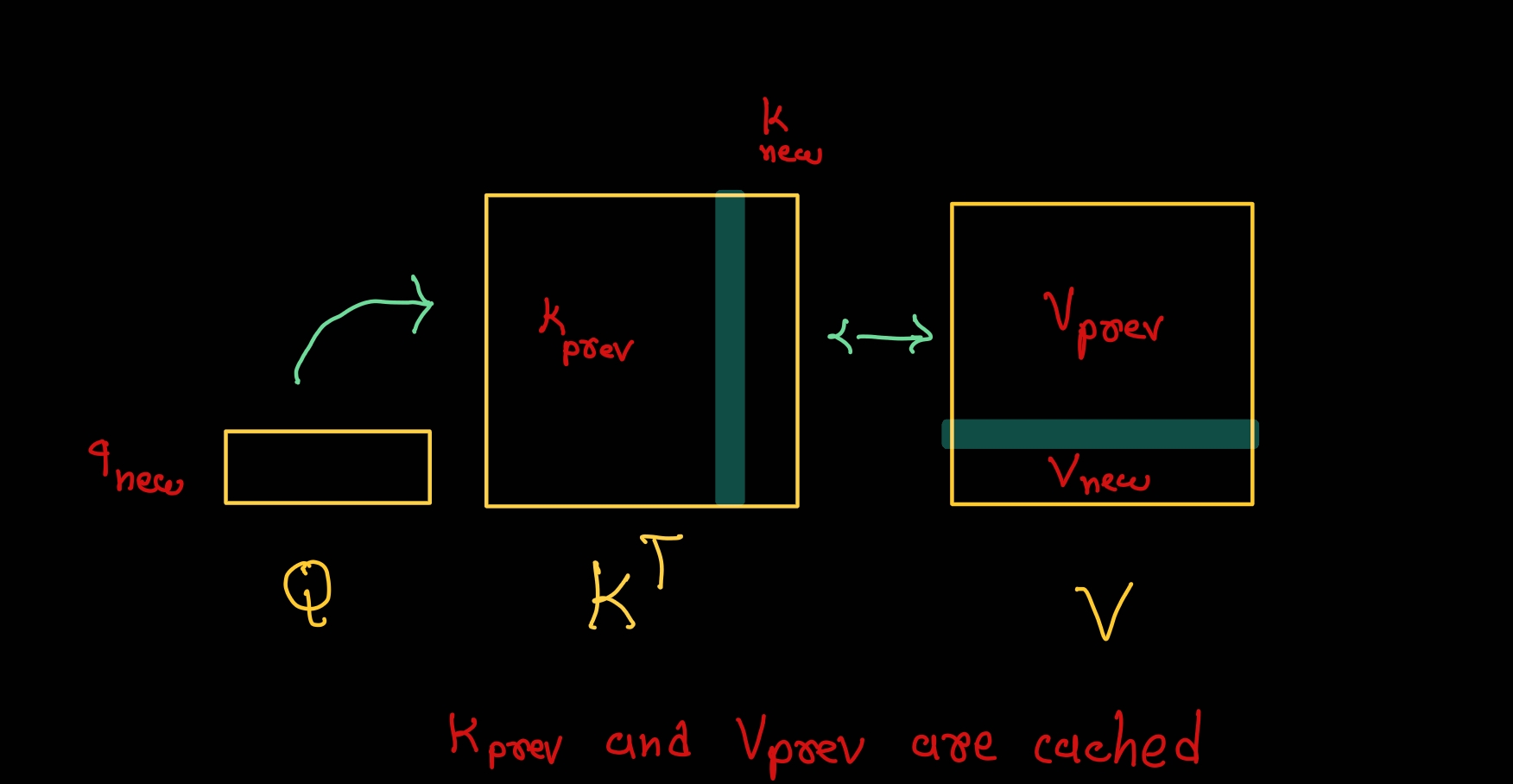
从KV Cache到Prompt Cache的应用
Shadow Walker 松烟阁
·

DeepSeek-V3.2-Exp:用稀疏注意力实现更高效的长上下文推理
我爱自然语言处理
·

