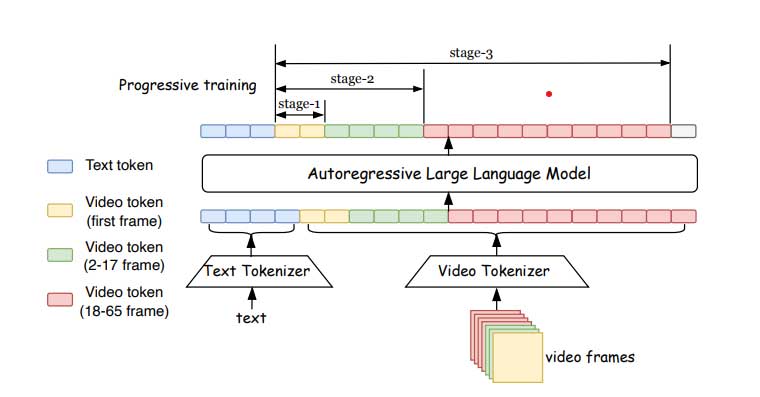
自回归大语言模型在视频生成中有潜力,但目前仅限短视频。Loong模型通过短到长训练和损失重加权,解决长视频生成中的问题。它使用3D CNN架构,将视频压缩为离散token序列,结合文本生成长视频。适用于低分辨率视频,未来可用于视觉艺术和娱乐,但需注意虚假内容生成。
本研究提出了一种名为Loong的新型自回归模型,通过将文本和视频标记统一建模,并采用渐进式训练方法,提升了生成长视频的能力。该模型能从10秒视频扩展生成符合文本提示的长视频,具有创新性和实用性。
完成下面两步后,将自动完成登录并继续当前操作。