
LOONG:一款基于自回归 LLM 的新型视频生成器,可生成长达一分钟的视频
内容提要
自回归大语言模型在视频生成中有潜力,但目前仅限短视频。Loong模型通过短到长训练和损失重加权,解决长视频生成中的问题。它使用3D CNN架构,将视频压缩为离散token序列,结合文本生成长视频。适用于低分辨率视频,未来可用于视觉艺术和娱乐,但需注意虚假内容生成。
关键要点
-
自回归大语言模型在视频生成中有潜力,但目前仅限短视频。
-
Loong模型通过短到长训练和损失重加权,解决长视频生成中的问题。
-
Loong使用3D CNN架构,将视频压缩为离散token序列,结合文本生成长视频。
-
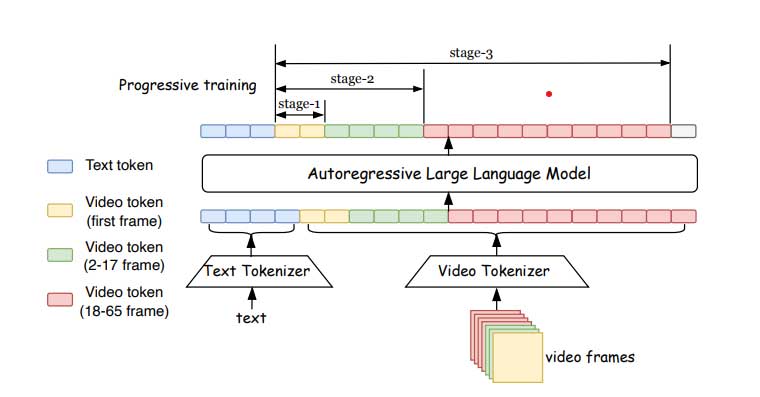
模型训练分为三个阶段:预训练、短视频训练和长视频联合训练。
-
Loong适用于低分辨率视频,未来可用于视觉艺术和娱乐。
-
需注意虚假内容生成的风险。
延伸解读
长视频生成的挑战与解决方案
Loong模型通过渐进式短到长训练和损失重加权来解决长视频生成中的损失不平衡问题。这种方法使得模型能够在训练初期专注于短视频,逐步扩展到长视频,从而提高生成质量。理解这一过程对于开发更高效的视频生成技术至关重要。
虚假内容生成的风险
尽管Loong在生成长视频方面展现了潜力,但其也可能被滥用来创造虚假内容。这一风险提醒我们在使用此类技术时需保持警惕,尤其是在信息传播日益迅速的当今社会。
模型架构与应用前景
Loong采用3D CNN架构和自回归LLM,能够生成外观一致且动态流畅的长视频。这一技术不仅适用于娱乐行业,还可能为视觉艺术创作带来新的可能性,值得相关领域的从业者关注。
延伸问答
Loong模型的主要功能是什么?
Loong模型是一种基于自回归大语言模型的视频生成器,能够生成长达一分钟的视频。
Loong模型是如何解决长视频生成中的问题的?
Loong模型通过短到长训练和损失重加权的方法,缓解了长视频生成中的损失不平衡问题。
Loong模型的训练过程分为几个阶段?
Loong模型的训练过程分为三个阶段:预训练、短视频训练和长视频联合训练。
Loong模型适用于什么类型的视频?
Loong模型适用于低分辨率视频,未来可用于视觉艺术和娱乐。
使用Loong模型生成视频时需要注意什么?
使用Loong模型生成视频时需注意可能生成虚假内容和传递误导性信息的风险。
Loong模型的架构是什么样的?
Loong模型采用3D CNN架构,将视频压缩为离散token序列,并结合文本生成视频。
