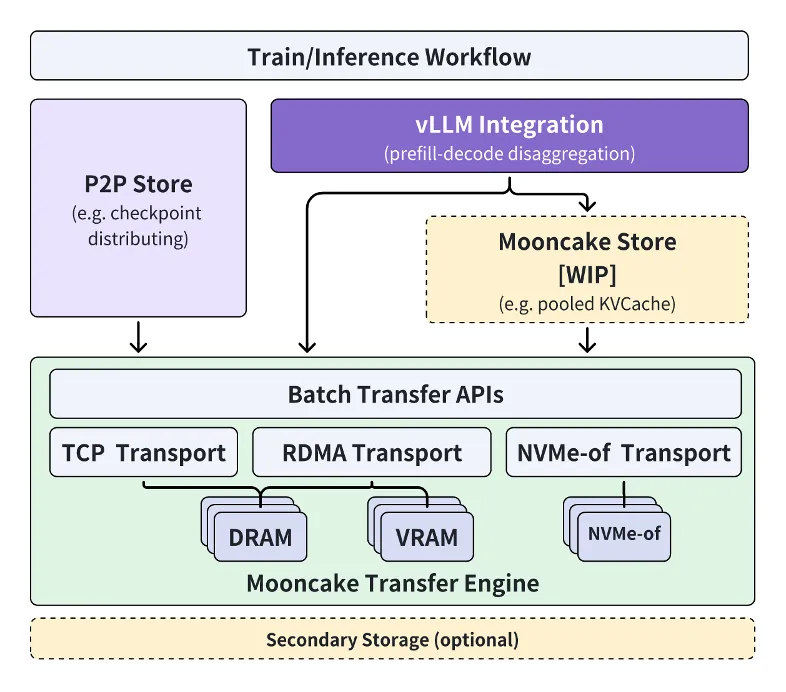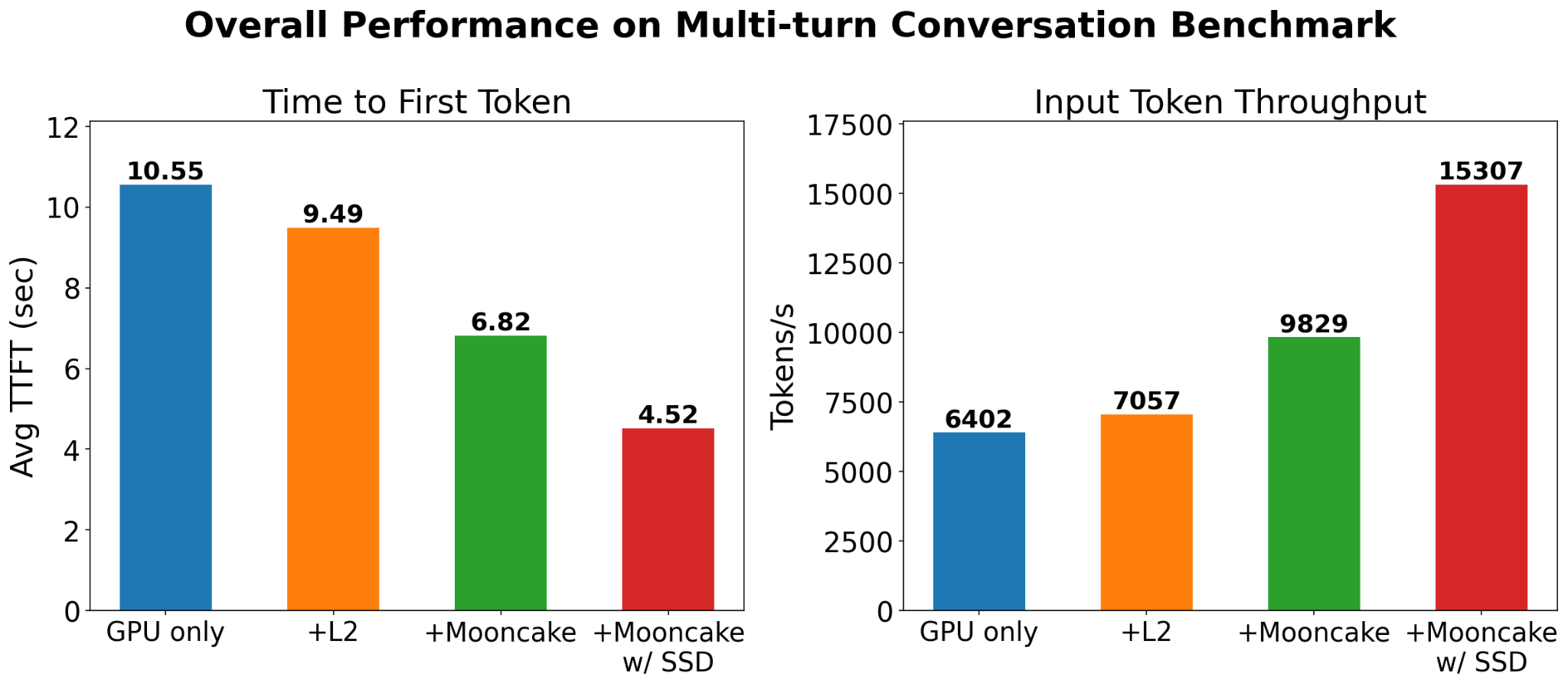
通过Mooncake SSD离线存储扩展KV缓存超越内存
Home | KVCache.ai
·

Mooncake正式加入PyTorch生态系统
Home | KVCache.ai
·

Mooncake为Databricks带来了丰富的事务处理能力
The New Stack
·

Mooncake Labs加入Databricks,加速Lakebase愿景
Databricks
·