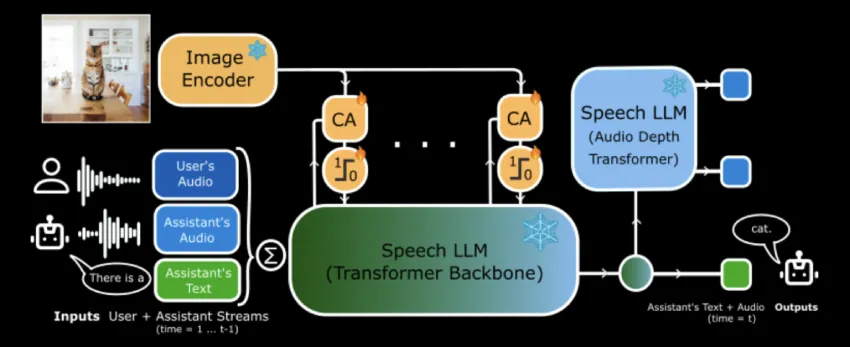
MoshiVis是一种开源视觉语音模型,结合实时语音交互与视觉内容,提升了对视觉场景的描述能力,特别适合视障人士。它通过轻量级交叉注意模块增强语音模型,确保低延迟和高效能,促进自然交互与可访问性。
完成下面两步后,将自动完成登录并继续当前操作。