
Kyutai 发布 MoshiVis:可实现图像的自然、实时语音交互的开源实时语音模型
内容提要
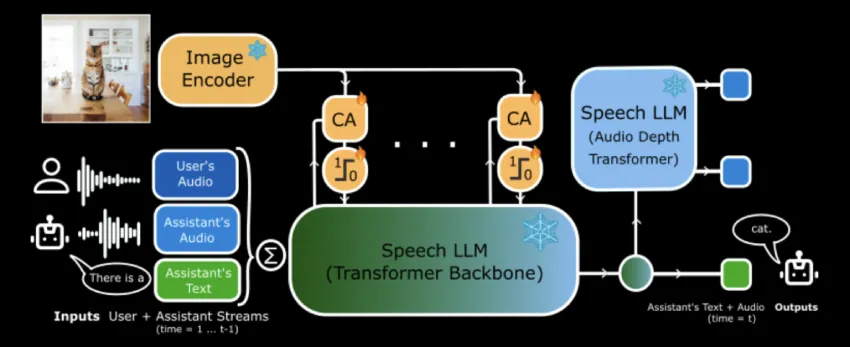
MoshiVis是一种开源视觉语音模型,结合实时语音交互与视觉内容,提升了对视觉场景的描述能力,特别适合视障人士。它通过轻量级交叉注意模块增强语音模型,确保低延迟和高效能,促进自然交互与可访问性。
关键要点
-
MoshiVis是一种开源视觉语音模型,结合实时语音交互与视觉内容,提升对视觉场景的描述能力。
-
传统系统依赖单独组件进行语音活动检测、语音识别等,可能引入延迟,无法捕捉人类对话的细微差别。
-
MoshiVis通过集成轻量级交叉注意模块增强语音模型,确保低延迟和高效能。
-
MoshiVis在消费级设备上每个推理步骤增加约7毫秒的延迟,总共55毫秒,低于实时延迟的80毫秒阈值。
-
MoshiVis能够提供详细的视觉场景描述,适用于视障人士的音频描述和增强可访问性。
-
Kyutai将MoshiVis作为开源项目发布,鼓励研究界和开发人员探索和扩展这项技术。
-
MoshiVis的开源性质促进了视觉语音模型的创新,推动更自然的技术交互。
-
MoshiVis代表了人工智能的重大进步,朝着多模式理解的无缝集成迈进。
延伸解读
技术背景与挑战
MoshiVis的推出解决了传统语音交互系统的局限性,尤其是在处理视觉信息时。以往的系统往往依赖多个独立组件,导致延迟和信息丢失。MoshiVis通过集成轻量级交叉注意模块,确保了实时性和准确性,特别适合需要快速反应的应用场景。
对视障人士的影响
MoshiVis的设计特别关注视障人士的需求,能够提供详细的视觉场景描述。这种技术的应用不仅提升了他们的生活质量,还为无障碍技术的发展开辟了新的方向。通过自然语音与视觉信息的结合,视障人士能够更好地理解周围环境。
开源的意义
MoshiVis作为开源项目发布,鼓励研究者和开发者参与到技术的改进中。这种开放性不仅促进了创新,还可能加速视觉语音模型的多样化应用,推动相关领域的进步。开源的特性使得更多人能够利用这一技术,推动社会的整体可访问性。
延伸问答
MoshiVis是什么?
MoshiVis是一种开源视觉语音模型,结合实时语音交互与视觉内容,提升对视觉场景的描述能力。
MoshiVis如何提高语音交互的效率?
MoshiVis通过集成轻量级交叉注意模块,确保低延迟和高效能,使得语音交互更加自然流畅。
MoshiVis对视障人士有什么帮助?
MoshiVis能够提供详细的视觉场景描述,适用于视障人士的音频描述,增强可访问性。
MoshiVis的延迟表现如何?
MoshiVis在消费级设备上每个推理步骤增加约7毫秒的延迟,总共55毫秒,低于实时延迟的80毫秒阈值。
Kyutai为什么选择将MoshiVis开源?
Kyutai将MoshiVis作为开源项目发布,鼓励研究界和开发人员探索和扩展这项技术,促进视觉语音模型的创新。
MoshiVis在人工智能领域的意义是什么?
MoshiVis代表了人工智能的重大进步,将视觉理解与实时语音交互相结合,推动了多模式理解的无缝集成。
