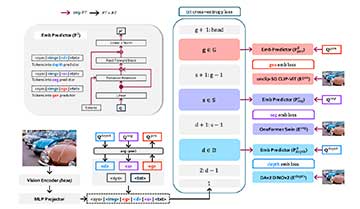
多模态大型语言模型(MLLM)正在迅速发展,能够同时处理文本和视觉数据。研究人员提出的OLA-VLM方法通过嵌入优化提升视觉理解,显著提高了模型在视觉任务中的表现,且在效率和性能上优于现有模型,为未来多模态系统的发展奠定了基础。
本研究提出OLA-VLM方法,以提升多模态大型语言模型的视觉理解能力。通过优化视觉嵌入,研究表明该方法在多个基准测试中平均提升性能2.5%,在深度任务中提高8.7%,显著增强视觉认知效果。
完成下面两步后,将自动完成登录并继续当前操作。