机器之心数据服务现已上线,提供高效稳定的数据获取服务,帮助用户轻松获取所需数据。
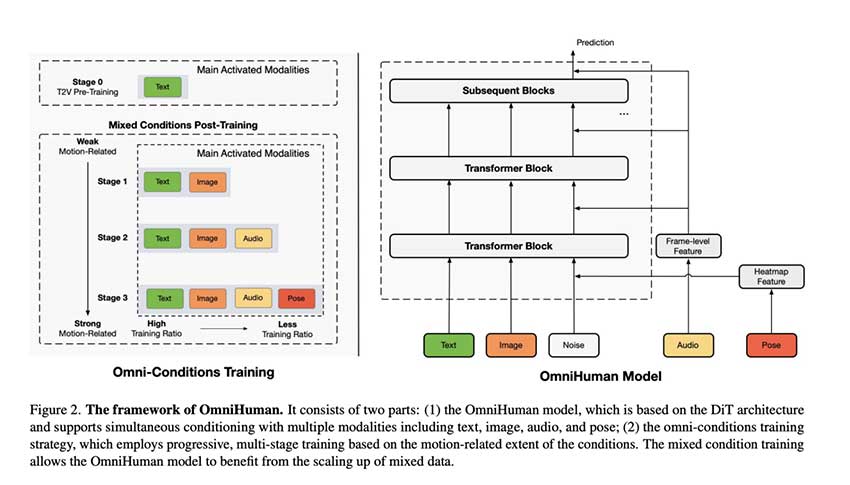
OmniHuman-1是一种先进的AI驱动人类视频生成模型,能够通过单一图像和音频生成逼真的人类动画。该模型基于DiT架构,采用混合条件训练策略,显著提升了动画质量和适应性,具有广泛的应用潜力,如医疗、教育和互动故事讲述。
即梦AI推出OmniHuman新功能,用户可通过图片和音频生成生动的AI视频。该模型支持多种图片尺寸,能生成与音频匹配的动作,改善手势表现。尽管效果自然,但影视真实级别视频生成仍需提升。即梦将进行小范围内测,并设置安全审核机制,确保技术的正面应用。
字节跳动推出的OmniHuman方案能够根据单张图片和音频生成生动的人物视频,支持多种输入形式,并显著改善手势崩坏问题。该技术通过混合多模态训练,克服了高质量数据稀缺的挑战,提升了生成效果。
OmniHuman-1是字节跳动推出的基于扩散变换器的AI模型,能够从单一图像生成逼真的人体动画。该模型结合多模态输入,支持音频和视频驱动,适应不同身体比例,提升动作真实感,克服了传统模型的局限性,表现出色,标志着AI人体动画的重大进步。
完成下面两步后,将自动完成登录并继续当前操作。