

如何优化PySpark作业:理解逻辑计划的实际场景
freeCodeCamp.org
·

PySpark原生绘图
Databricks
·
PySpark UDF统一性能分析
Databricks
·

在Kubernetes上部署的PySpark与Jupyter Notebook
DEV Community
·

Apache PySpark
DEV Community
·

学习笔记 6.13-14:使用Python的Kafka流处理与使用PySpark的结构化流处理
DEV Community
·

在Windows笔记本上运行PySpark本地Python
DEV Community
·



Azure Synapse PySpark 工具箱 001:输入/输出
DEV Community
·

如何在本地机器上安装PySpark
DEV Community
·

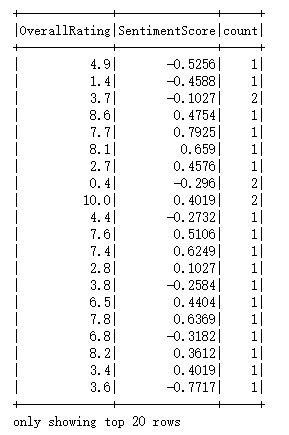
基于英国航空公司客户反馈数据的PySpark数据处理与分析
厦大数据库实验室博客
·

2023 年的 PySpark:年度回顾
Databricks
·


