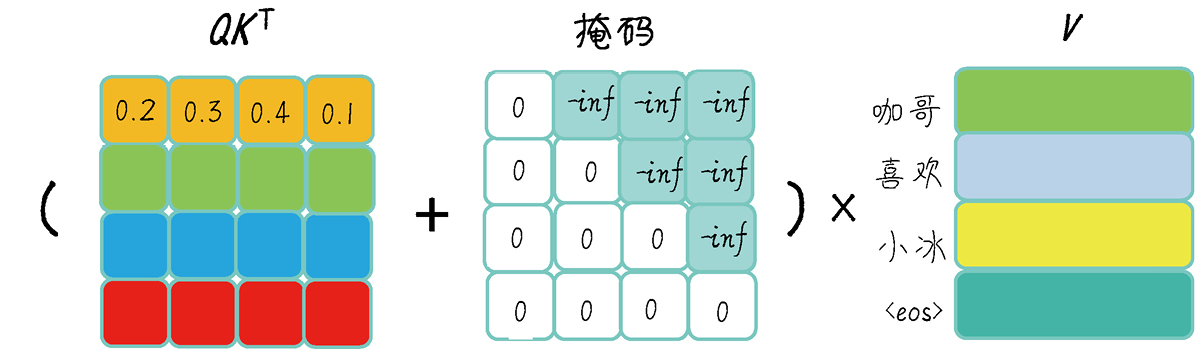
本文探讨了注意力机制中的QKV、多头注意力和掩码。QKV分别代表查询、键和值,通过矩阵变换提取特征。多头注意力将输入分为多个子空间,从不同角度学习特征。掩码用于将不重要的信息权重设为接近“0”,以优化注意力计算。
本研究探讨了大语言模型中的键值缓存压缩技术,提出了多种量化方法以提高内存效率和推理速度。通过KIVI、LESS、MiKV等算法,显著降低了内存占用并提升了吞吐量,优化了模型性能。这些方法在保持生成质量的同时,实现了高压缩比和更大的上下文长度,为资源受限环境中的大语言模型应用提供了新思路。
该文介绍了一种基于键值记忆的注意力机制模型,用于神经机器翻译。该模型通过维护及时更新的键内存和固定值内存来存储源语句的表示,以便在每个解码步骤时,可以关注更合适的源单词来预测下一个目标单词,从而提高翻译的适用性。实验结果表明该模型在中英文和WMT17德英翻译任务中表现优越。
完成下面两步后,将自动完成登录并继续当前操作。