README驱动开发(RDD)强调在编码前撰写README文档,以明确项目目标和使用方法。这种方法有助于项目规划、吸引贡献者并保持文档更新。尽管RDD可能不适用于快速变化的项目,但它能提高开发效率,确保良好的文档基础。
在大数据领域,Spark的弹性分布式数据集(RDD)通过持久化提高性能和容错能力。RDD缓存可以在集群故障时重计算丢失的分区,确保数据处理的稳健性,并显著提升未来操作的性能。Spark还支持超出内存限制的大数据集,通过“内存+磁盘”方式高效处理。RDD持久化对迭代算法和重复操作尤为重要,是优化Spark应用的关键。
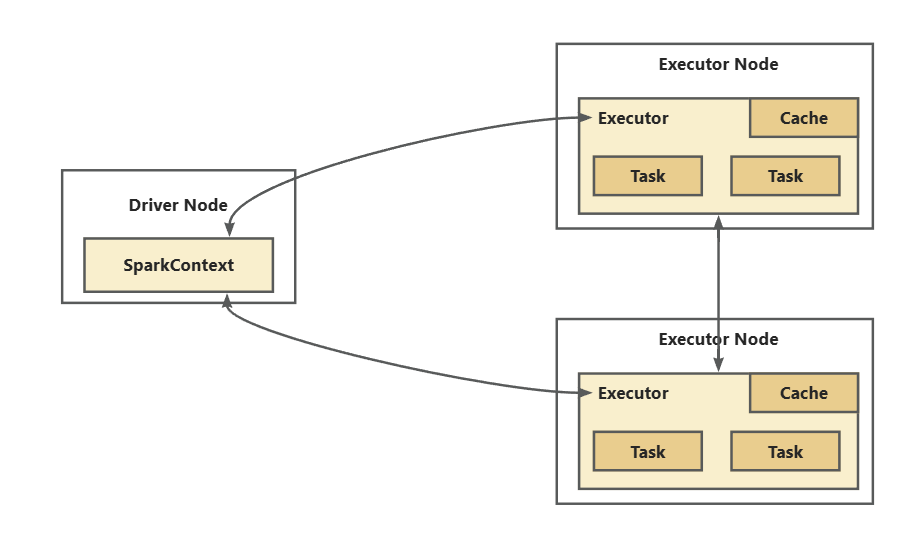
Spark是一个基于内存的分布式计算框架,支持SQL、图处理和机器学习,适合数据清洗和聚合。它通过并行计算和资源管理解决大数据处理问题,运行于K8S集群,使用spark-submit和spark-operator管理应用。核心概念包括弹性分布式数据集(RDD)和任务调度,SparkSQL模块优化SQL执行效率。与Hadoop相比,Spark在速度和易用性上更具优势,但对内存要求较高。
本文介绍了Spark Core的基本功能和应用场景,RDD的特性和转换算子和行动算子的使用,共享变量的使用方法和原理,内核调度和DAG的作用,宽窄依赖和内存迭代计算的优势,并行度设置和Shuffle阶段的工作原理,以及任务调度和层级关系。
《Spark编程基础(Python版,第2版)》是由厦门大学林子雨编著的教材,提供了命令行和代码示例,包括文件操作、数据处理、排序等内容。还介绍了在PyCharm中调试程序的方法。
本文讨论了flink和spark的反压机制、cp和sp的原理和区别、消费kafka的offset维护、RDD的定义、四个图的概念、barrier对齐和非对齐的理解、spark与mapreduce的区别以及精准一次和至少一次的理解。
Spark Core是Apache Spark的核心组件之一,提供了易于编程、高速计算、迭代计算等特点的分布式计算能力,可直接从多种数据源中读取数据。其基本数据结构为RDD,可进行大规模数据并行处理,具有容错性和基于主存进行缓存的特点。Spark Core采用内存计算模式,减少了I/O瓶颈,提高了计算速度。
完成下面两步后,将自动完成登录并继续当前操作。