
spark原理解析
内容提要
Spark是一个基于内存的分布式计算框架,支持SQL、图处理和机器学习,适合数据清洗和聚合。它通过并行计算和资源管理解决大数据处理问题,运行于K8S集群,使用spark-submit和spark-operator管理应用。核心概念包括弹性分布式数据集(RDD)和任务调度,SparkSQL模块优化SQL执行效率。与Hadoop相比,Spark在速度和易用性上更具优势,但对内存要求较高。
关键要点
-
Spark是一个基于内存的分布式计算框架,支持SQL、图处理和机器学习。
-
Spark主要解决计算的并行化、集群资源管理、容错与恢复等问题。
-
Spark适用于对大量离线数据进行清洗、转换和聚合。
-
在K8S集群中,Spark通过spark-submit和spark-operator管理应用。
-
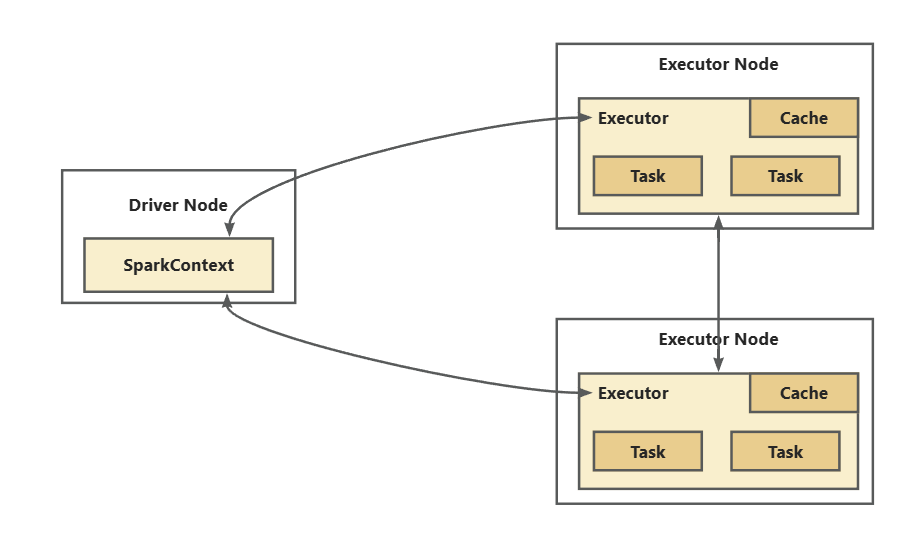
Spark的核心概念包括弹性分布式数据集(RDD)和任务调度。
-
SparkSQL模块优化SQL执行效率,支持多种编程语言。
-
Spark的任务执行基于DAG(有向无环图)模型,帮助组织和优化作业。
-
Spark通过shuffle机制提高数据处理效率,尤其在join操作中。
-
SparkSQL通过Catalyst优化器自动优化用户输入的SQL,提高执行效率。
-
Hadoop是一个分布式处理框架,主要使用MapReduce模型,效率较低。
-
Spark在速度和易用性上优于Hadoop,但对内存要求较高。
-
odps是阿里云的核心大数据处理平台,针对特定场景进行了优化。
-
odps在存储、计算、调度等多个层面进行了深度优化,性能优于Spark。
-
odps通过定制化的网络协议和高效的数据压缩机制优化shuffle操作。
-
odps内置高度优化的SQL查询引擎,能够高效运行复杂查询。
延伸解读
Spark与Hadoop的比较
Spark和Hadoop在大数据处理上各有优势。Spark通过内存计算显著提高了处理速度,适合需要快速迭代的场景,而Hadoop则在生态系统的成熟度和稳定性上更具优势。对于预算有限或实时性要求不高的项目,Hadoop可能是更具成本效益的选择。
SparkSQL的优化机制
SparkSQL利用Catalyst优化器自动优化用户的SQL查询,提高执行效率。通过逻辑计划的优化和物理计划的选择,SparkSQL能够在处理复杂查询时减少I/O消耗,提升整体性能。这使得非程序员也能更方便地进行大数据分析。
odps的优势
odps作为阿里云的核心大数据处理平台,在存储、计算和调度等方面进行了深度优化,尤其在处理超大规模数据时表现优异。其内置的SQL查询引擎和针对性优化使得在特定场景下,odps的性能往往优于Spark,值得关注。
延伸问答
Spark的主要功能和应用场景是什么?
Spark是一个基于内存的分布式计算框架,支持SQL、图处理和机器学习,主要用于对大量离线数据进行清洗、转换和聚合。
Spark如何在K8S集群中管理应用?
Spark在K8S集群中通过spark-submit和spark-operator管理应用,前者是命令行工具,后者是开源组件,提供更结构化的配置管理。
Spark的核心概念是什么?
Spark的核心概念包括弹性分布式数据集(RDD)和任务调度,RDD是一种容错的数据结构,支持并行操作。
SparkSQL如何优化SQL执行效率?
SparkSQL通过Catalyst优化器自动优化用户输入的SQL,生成高效的执行计划,提高执行效率。
Spark与Hadoop相比有哪些优势?
Spark在速度和易用性上优于Hadoop,能够在内存中完成大部分计算,适合快速迭代和交互式查询,但对内存要求较高。
odps与Spark的主要区别是什么?
odps在存储、计算和调度等方面进行了深度优化,特别是在批处理和海量数据处理场景中性能优于Spark。
