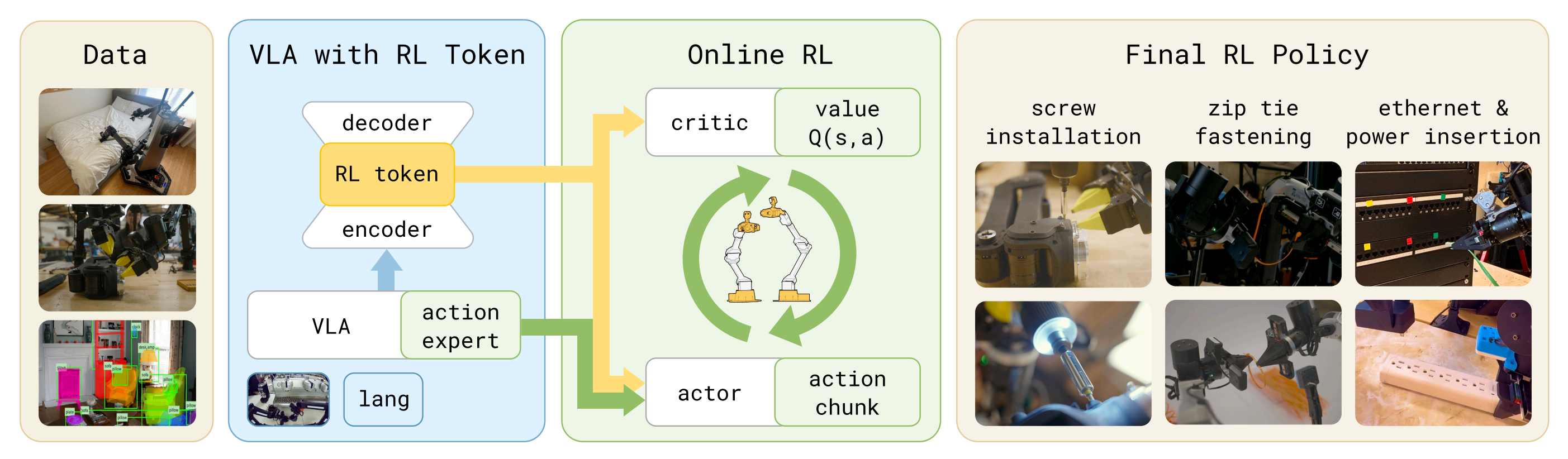
本文讨论了一种轻量级的在线强化学习方法,用于微调视觉-语言-动作模型。研究者通过引入“RL token”提高样本效率,使得模型能够快速适应真实世界任务。该方法结合冻结的VLA和小型actor-critic网络,优化关键任务阶段的表现,旨在实现高效的在线微调,同时保持泛化能力。
卡内基梅隆大学提出的Run-Length Tokenization(RLT)方法通过合并重复图像块,显著提高视频生成模型的训练和推理速度,训练时间减少30%,推理时间减少67%,且精度损失极小,特别适用于高帧率和长视频。
最近作者在工作中需要一个高性能的压力测试工具,但常见的压测工具都用不了,于是自己动手写了一个叫 rlt 的库,可以用于各种服务的压测,包括 http, grpc, thrift, database 或者其他自定义的协议。rlt 还提供了一个带实时反馈的 TUI 界面。
完成下面两步后,将自动完成登录并继续当前操作。