

mAceReason-Math:一个高质量的多语言数学问题数据集,支持强化学习与可验证奖励(RLVR)
Apple Machine Learning Research
·

揭秘!RLVR/GRPO中那些长期被忽略的关键缺陷
机器之心
·

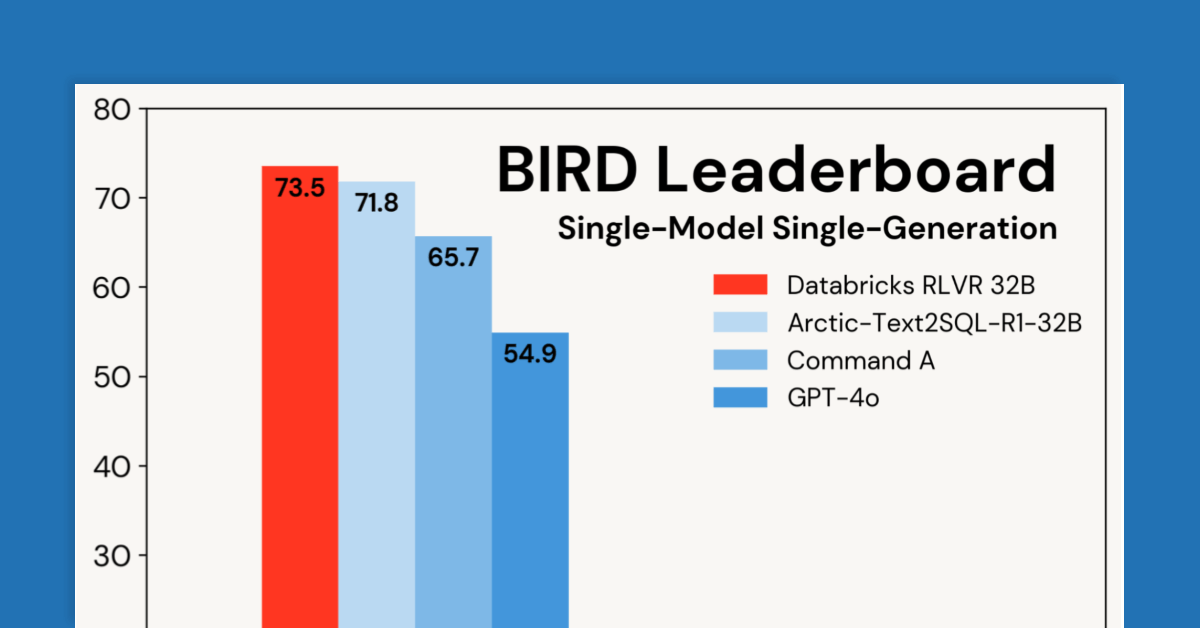
RLVR的力量:在Databricks上训练领先的SQL推理模型
Databricks
·

RLVR并未扩展大型语言模型的推理能力,仅优化了采样行为:新研究
DEV Community
·
