
RLVR的力量:在Databricks上训练领先的SQL推理模型
内容提要
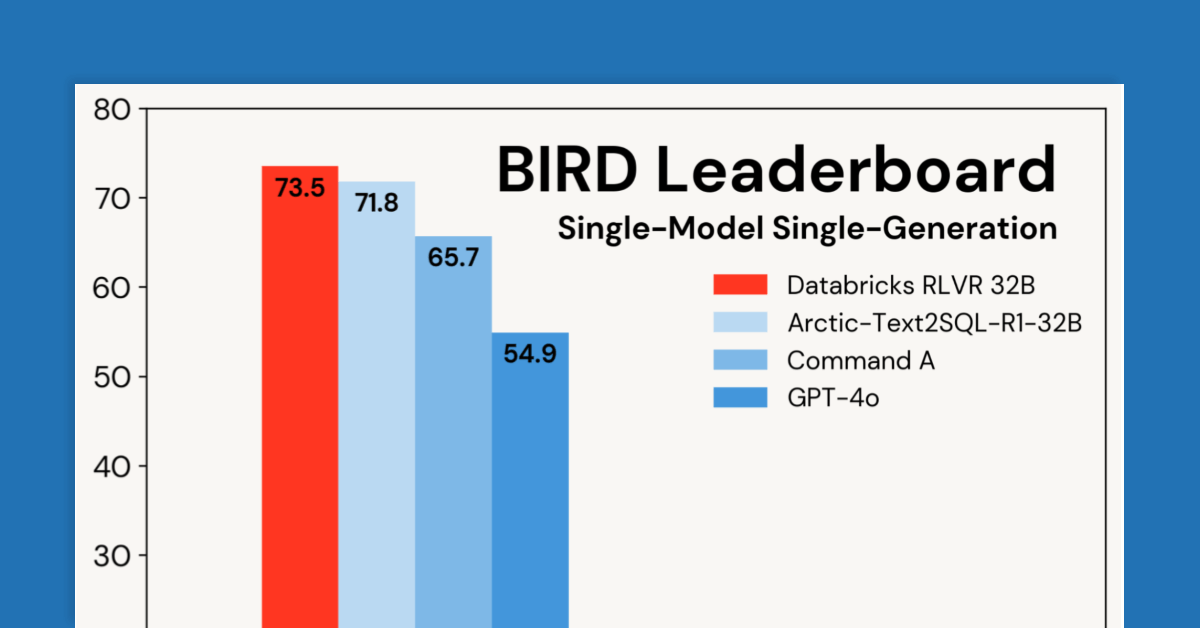
在Databricks,我们通过可验证奖励的强化学习(RLVR)开发推理模型,解决客户问题并提升产品性能。在BIRD基准测试中,我们取得73.5%的新高,证明了RLVR的有效性和易用性,帮助用户更好地与数据互动。
关键要点
-
Databricks使用可验证奖励的强化学习(RLVR)开发推理模型,解决客户问题并提升产品性能。
-
RLVR适用于生成代码、数据分析、整合组织知识、领域特定评估和信息提取等任务。
-
在BIRD基准测试中,Databricks的RLVR模型取得73.5%的新高,证明了其有效性和易用性。
-
BIRD基准测试用于将自然语言查询转换为SQL代码,帮助非SQL专家与数据互动。
-
Databricks的RLVR模型在BIRD基准测试中表现优异,超越了之前的最佳成绩71.8%。
-
使用标准的RLVR组件和BIRD训练集,Databricks实现了显著的性能提升。
-
通过精心选择模型和提示,Databricks在BIRD基准测试中取得了领先地位。
-
Databricks客户在推理领域也报告了使用RLVR训练堆栈的良好结果,显示其广泛适用性。
延伸解读
RLVR的应用场景
可验证奖励的强化学习(RLVR)在多个领域展现出广泛的适用性,包括代码生成、数据分析和信息提取等。这使得非专业用户能够更轻松地与数据进行互动,尤其是在SQL查询方面,降低了技术门槛。
BIRD基准测试的重要性
BIRD基准测试是评估自然语言查询转SQL代码能力的重要工具。尽管它无法完全反映现实世界的复杂性,但其标准化的测试环境为模型性能提供了可靠的衡量依据,帮助开发者优化推理模型。
RLVR的优势与局限
RLVR的主要优势在于其简单性和通用性,能够在标准数据集上取得显著的性能提升。然而,依赖于特定数据集的训练可能导致模型在其他场景中的表现不佳,因此在实际应用中需谨慎评估其适用性。
延伸问答
什么是可验证奖励的强化学习(RLVR)?
可验证奖励的强化学习(RLVR)是一种强化学习方法,利用可直接验证的奖励来训练模型,适用于生成代码、数据分析等任务。
Databricks在BIRD基准测试中的表现如何?
Databricks在BIRD基准测试中取得了73.5%的新高,超越了之前的最佳成绩71.8%。
BIRD基准测试的目的是什么?
BIRD基准测试旨在将自然语言查询转换为SQL代码,帮助非SQL专家与数据互动。
Databricks的RLVR模型适用于哪些任务?
RLVR模型适用于生成代码、数据分析、整合组织知识、领域特定评估和信息提取等任务。
Databricks如何提升其SQL推理模型的性能?
Databricks通过使用标准的RLVR组件和BIRD训练集,结合精心选择的模型和提示,显著提升了SQL推理模型的性能。
客户在使用Databricks的RLVR训练堆栈时有什么反馈?
Databricks的客户在推理领域报告了使用RLVR训练堆栈的良好结果,显示其广泛适用性。
