
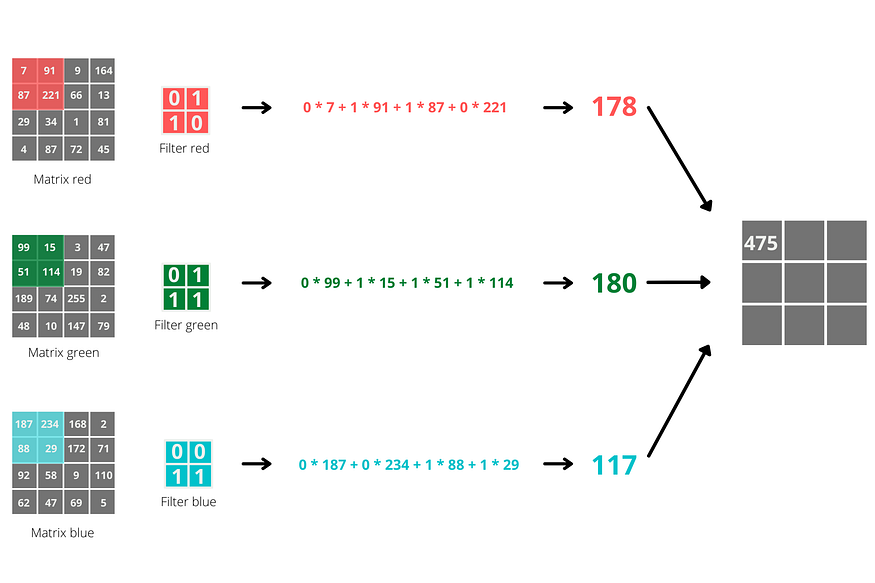
卷积神经网络、递归神经网络与变换器解析:深度学习关键概念的思维模型
freeCodeCamp.org
·
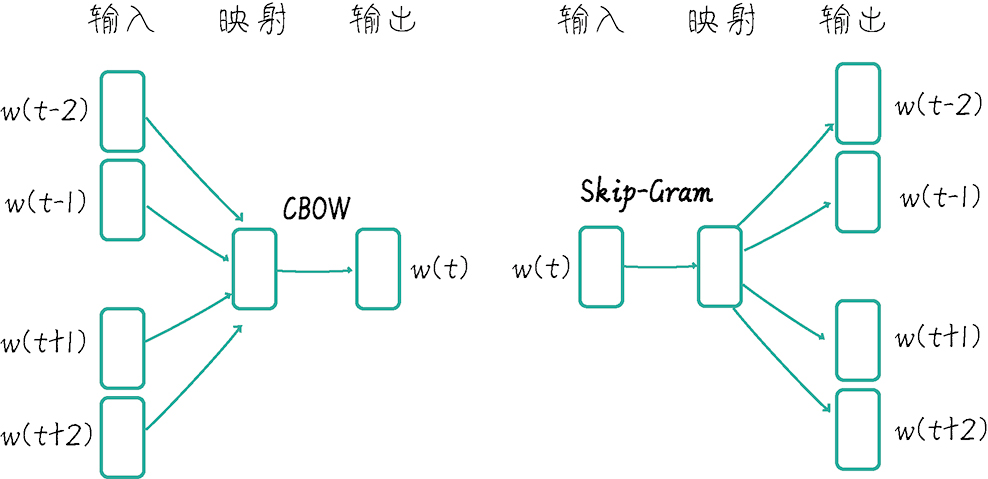
《GPT 图解》笔记:N-Gram、NPLM、LSTM
Ying’s Blog
·


小猫都能懂的大模型原理 3 - 自注意力机制
UsubeniFantasy
·



破解深度学习的密码:开发者和梦想者必读
DEV Community
·

破解深度学习的密码:开发者和梦想者必读
DEV Community
·
