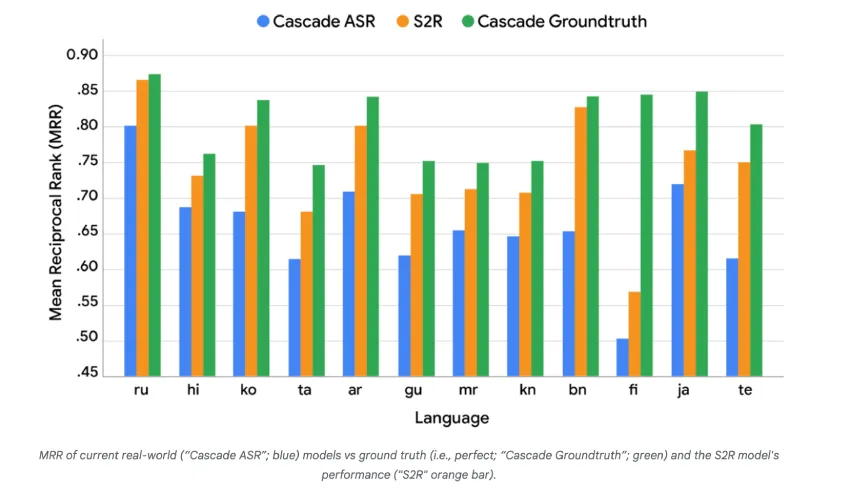
S2R技术通过直接理解用户语音意图,避免了传统语音转录的局限,提升了搜索准确性和用户体验。该技术在多语言环境中表现优异,适用于智能助手和车载系统,推动了语音交互的包容性和人性化。
S2R技术通过直接理解语音中的用户意图,避免了传统语音转录的局限,提升了搜索准确性和用户体验。该技术在多语言环境中表现出色,适用于智能助手和车载系统,推动语音交互的包容性与人性化。
S2R技术通过直接理解语音中的用户意图,避免了传统语音转录的局限,提升了语音搜索的准确性和用户体验。该技术在多语言环境中表现优异,适用于智能助手和车载系统,推动了人机交互的发展。
语音检索技术(S2R)正在迅速发展,提升了人机沟通的速度和准确性。该技术通过直接解读音频信息,克服了传统语音转文本的延迟和误解问题,支持多种语言和口音,改善用户体验。尽管面临数据处理和隐私挑战,S2R已成为语音助手和智能家居的关键技术,推动数字通信的未来。
谷歌通过语音转检索(S2R)技术实现了语音搜索的突破,直接将语音查询映射为嵌入向量,避免转录错误。S2R采用双编码器架构,优化检索意图,提升搜索质量。谷歌已将该技术投入生产,并开源相关数据集以支持社区发展。
本文介绍了多种基于Transformer的图像超分辨率模型,如Hybrid Attention Transformer、Swin Transformer和S2R。这些模型通过结合不同的注意力机制和预训练策略,显著提升了超分辨率性能,实验结果在多个基准测试中优于现有方法。
本文提出了一个名为S2R的双赢框架,包括一个轻量级的基于transformer的SR模型和一种新颖的自上而下的训练策略,可以在理想和随机模糊条件下实现出色的视觉结果。S2R transformer巧妙地组合了一些高效且轻量级的块,以增强提取特征的表示能力,并且具有相对较少的参数。实验结果表明,S2R在理想的SR条件下仅使用578K参数就优于其他单图像SR模型。同时,在盲模糊条件下,它可以实现比常规盲SR模型更好的视觉效果,仅使用10次渐变更新就提高了收敛速度300倍,显著加速了在现实世界情况下的迁移学习过程。
本文提出了一个双赢框架S2R,用于理想和盲SR任务。该框架包括一个轻量级的基于transformer的SR模型和一种自上而下的训练策略。实验结果表明,S2R在理想SR条件下优于其他模型,并在盲模糊条件下提高了收敛速度300倍。
完成下面两步后,将自动完成登录并继续当前操作。