
谷歌推出语音到检索(S2R)技术,无需先将语音转为文本即可检索信息
内容提要
谷歌通过语音转检索(S2R)技术实现了语音搜索的突破,直接将语音查询映射为嵌入向量,避免转录错误。S2R采用双编码器架构,优化检索意图,提升搜索质量。谷歌已将该技术投入生产,并开源相关数据集以支持社区发展。
关键要点
-
谷歌通过语音转检索(S2R)技术实现了语音搜索的重大突破,直接将语音查询映射为嵌入向量,避免转录错误。
-
S2R采用双编码器架构,音频编码器和文档编码器联合训练,以优化检索意图。
-
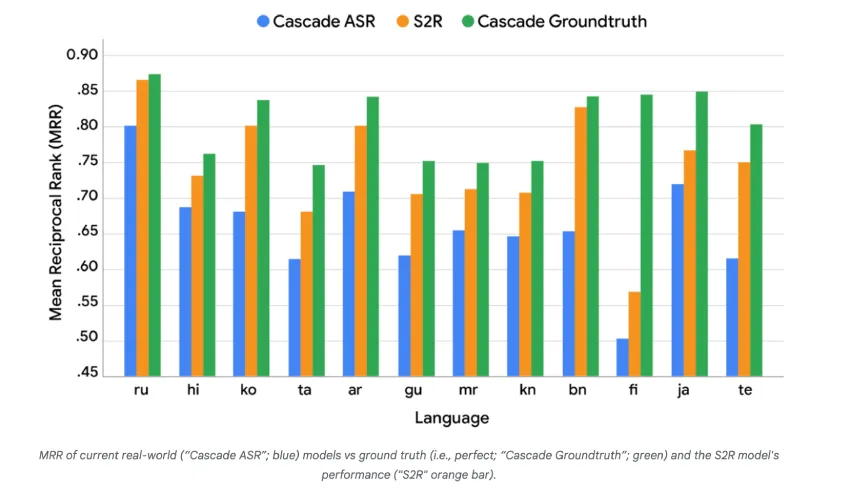
S2R在评估中表现优于传统的级联自动语音识别(ASR)方法,接近真实转录的上限。
-
谷歌已将S2R技术投入生产,并提供多种语言服务,集成到现有的搜索排名系统中。
-
谷歌开源了简单语音问题(SVQ)数据集,包含26个语言环境和17种语言,以支持社区发展和标准化语音检索基准测试。
-
S2R是一项深远的架构修正,旨在优化检索质量并消除级联误差源,未来工作将集中在音频相关性得分的校准和隐私权衡上。
延伸解读
技术背景与创新
谷歌的语音转检索(S2R)技术代表了语音搜索领域的一次重大创新。通过直接将语音查询映射为嵌入向量,S2R避免了传统自动语音识别(ASR)中可能出现的转录错误。这种方法不仅提高了检索的准确性,还使得系统能够更好地理解用户的检索意图,标志着语音搜索技术的一个新阶段。
双编码器架构的优势
S2R采用的双编码器架构,通过音频编码器和文档编码器的联合训练,能够有效捕捉语音查询的语义信息。这种设计使得音频查询与相关文档的向量在几何空间中更为接近,从而提升了检索的效率和准确性。这一架构的创新为未来的语音检索系统提供了新的思路。
开源数据集的意义
谷歌开源的简单语音问题(SVQ)数据集包含多种语言和环境的音频问题,为研究者提供了丰富的资源。这不仅促进了社区的技术发展,也为标准化语音检索基准测试奠定了基础。通过开放数据集,谷歌希望推动语音检索技术的进一步创新与应用。
延伸问答
什么是谷歌的语音转检索(S2R)技术?
S2R技术将语音查询直接映射为嵌入向量,无需将语音转为文本,从而避免转录错误。
S2R技术如何优化语音搜索的质量?
S2R采用双编码器架构,音频编码器和文档编码器联合训练,以优化检索意图,提升搜索质量。
S2R技术与传统的自动语音识别(ASR)方法相比有什么优势?
S2R在评估中表现优于传统的级联ASR方法,接近真实转录的上限,减少了转录错误对检索结果的影响。
谷歌如何支持社区发展S2R技术?
谷歌开源了简单语音问题(SVQ)数据集,包含26个语言环境和17种语言,以支持社区发展和标准化语音检索基准测试。
S2R技术的未来发展方向是什么?
未来工作将集中在音频相关性得分的校准和隐私权衡上,以进一步优化检索质量。
S2R技术是如何实现音频流传输和相似度搜索的?
在推理阶段,音频数据流式传输至预训练音频编码器生成查询向量,用于识别相关的候选结果集。
